Import documents / files
Written By Stanislas
Last updated 6 months ago
Upload files from your computer to build your knowledge base. Swiftask automatically extracts text from documents using OCR technology, processes them into searchable chunks, and makes them available to AI agents and teammates across your workspace.
Whether you need to upload PDFs, Word documents, spreadsheets, or code files, file import makes it easy to centralize your organization's knowledge in one place. Upload once, use everywhere—across Chat, Agents, and Projects.
Overview
The import documents feature lets you upload files directly from your computer to your knowledge base. Swiftask automatically processes your files—extracting text from images and PDFs using Mistral OCR technology, parsing structured data, and indexing everything for instant AI-powered search and retrieval.
You can upload multiple file types including documents (PDF, DOCX, TXT), spreadsheets (CSV, XLSX), code files (JSON, MD, etc.), and more. Each file is processed, chunked, and stored as a data source that agents and team members can access.
Prerequisites
To import documents to your knowledge base, you need:
A Swiftask account (sign up at swiftask.ai)
Access to the Knowledge section
Files on your computer (supported formats: PDF, DOCX, XLSX, CSV, TXT, JSON, code files, etc.)
Permission to create data sources in your workspace
File import is available to all Swiftask users.
Supported file types
Swiftask accepts a wide range of file formats:
Documents: PDF, DOCX, DOC, TXT
Spreadsheets: XLSX, XLS, CSV
Data formats: JSON, XML, MD
Code files: Python, JavaScript, and other programming language files
File size: Check your plan limits for maximum file size per upload
Step-by-step guide
1. Navigate to Knowledge
Click Knowledge in the left sidebar. You'll see the Knowledge interface with all your data sources and folders.
2. Click the Import button
In the Knowledge section, locate and click the Import button. A dropdown menu appears with multiple import options.
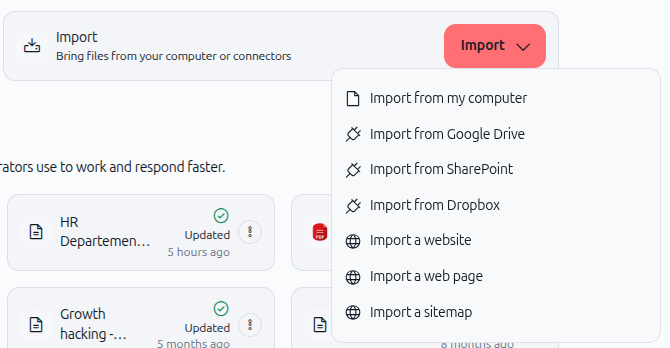
As shown in the image above, you'll see several import options:
Import from my computer – Upload files directly from your device
Import from Google Drive – Sync files from Google Drive
Import from SharePoint – Connect to SharePoint documents
Import from Dropbox – Sync files from Dropbox
Import a website – Scrape content from a website
Import a web page – Import a single web page
Import a sitemap – Import multiple pages from a sitemap
For this guide, select Import from my computer.
3. Configure your file import
The file import configuration screen opens. This is where you'll upload your files and configure how Swiftask processes them.
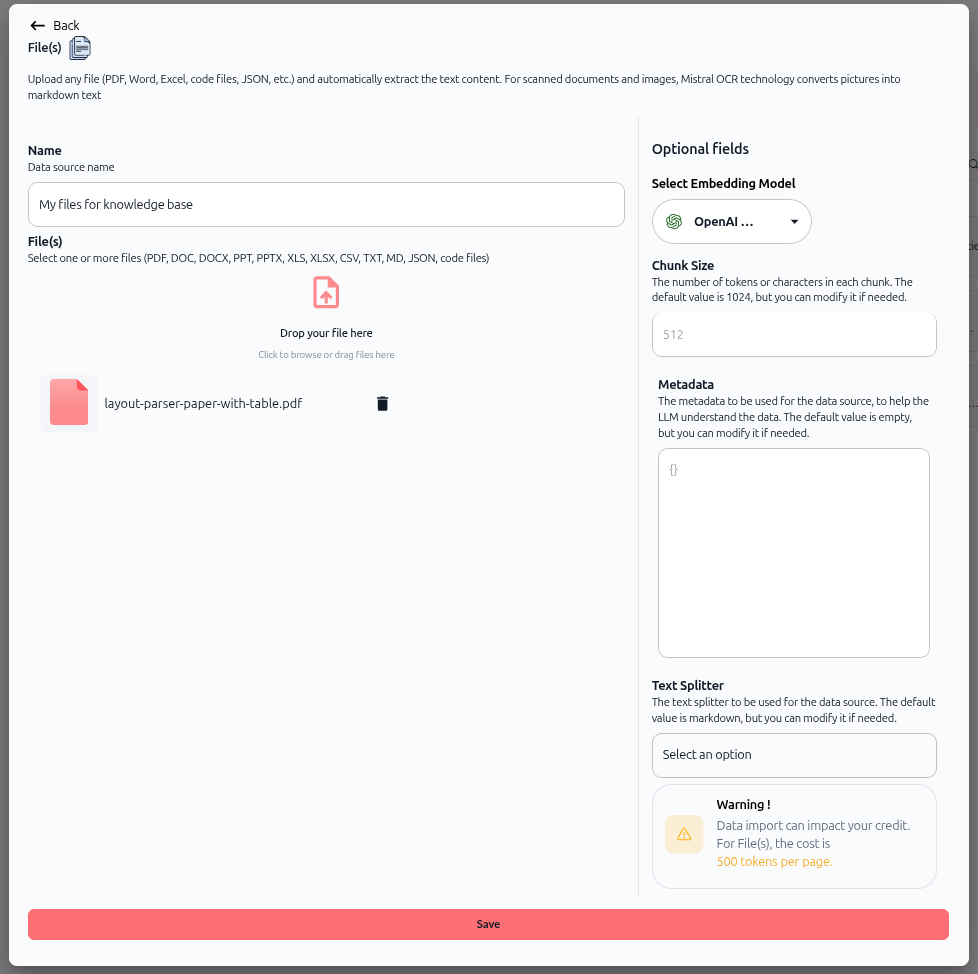
As shown in the image above, the screen is divided into two sections:
Left section: File upload
Name – Enter a descriptive name for your data source (e.g., "My Files for knowledge base")
File(s) – Drop your files here or click to browse. You can select one or multiple files (PDF, DOC, DOCX, PPT, PPTX, XLS, XLSX, CSV, TXT, MD, JSON, code files)
Right section: Optional fields
Select embedding model – Choose the AI model used to create vector embeddings of your content (default: OpenAI Text Embedding 3 Small). This determines how your content is indexed and searched
Chunk size – Set the number of tokens or characters in each chunk. The default is 512, but you can modify it if needed. Smaller chunks provide more precise retrieval; larger chunks provide more context
Metadata – Add custom metadata as JSON to help the AI understand your data. This field is optional but useful for adding context
Text splitter – Choose the method for splitting text content. The default is markdown, but you can select other options from the dropdown
Warning! – A cost indicator shows the credit consumption: "For File(s), the cost is 500 tokens per page"
The screen also mentions that Swiftask uses Mistral OCR technology to convert scanned documents and images into markdown text.
4. Upload your files
Option 1: Drag and drop
Drag files from your computer directly into the Drop your file here area.
Option 2: Browse and select
Click Click to browse or drag files here, then select files from your file system.
You can upload multiple files at once. Each file appears in the upload area with its name and a delete icon (trash) if you need to remove it.
5. Configure optional settings (if needed)
Embedding model: Leave the default (OpenAI Text Embedding 3 Small) unless you have specific requirements.
Chunk size: Keep the default (512) for most use cases. Adjust only if you need more granular or broader context retrieval.
Metadata: Add custom metadata if you want to provide additional context to the AI. For example:
{ "department": "HR", "year": "2025", "document_type": "policy" } Text splitter: Keep the default (markdown) unless your document requires a specific splitting method.
6. Save and process
Once your files are uploaded and configured, click the Save button at the bottom of the screen.
Swiftask processes your files in the background:
Text is extracted from PDFs and images using OCR
Content is split into chunks based on your chunk size setting
Chunks are embedded using the selected embedding model
The data source is indexed and made searchable
You'll see a progress indicator. Once complete, your data source appears in the Knowledge section.
7. View your imported documents
After processing, navigate back to the Knowledge section. Your new data source appears in the list.
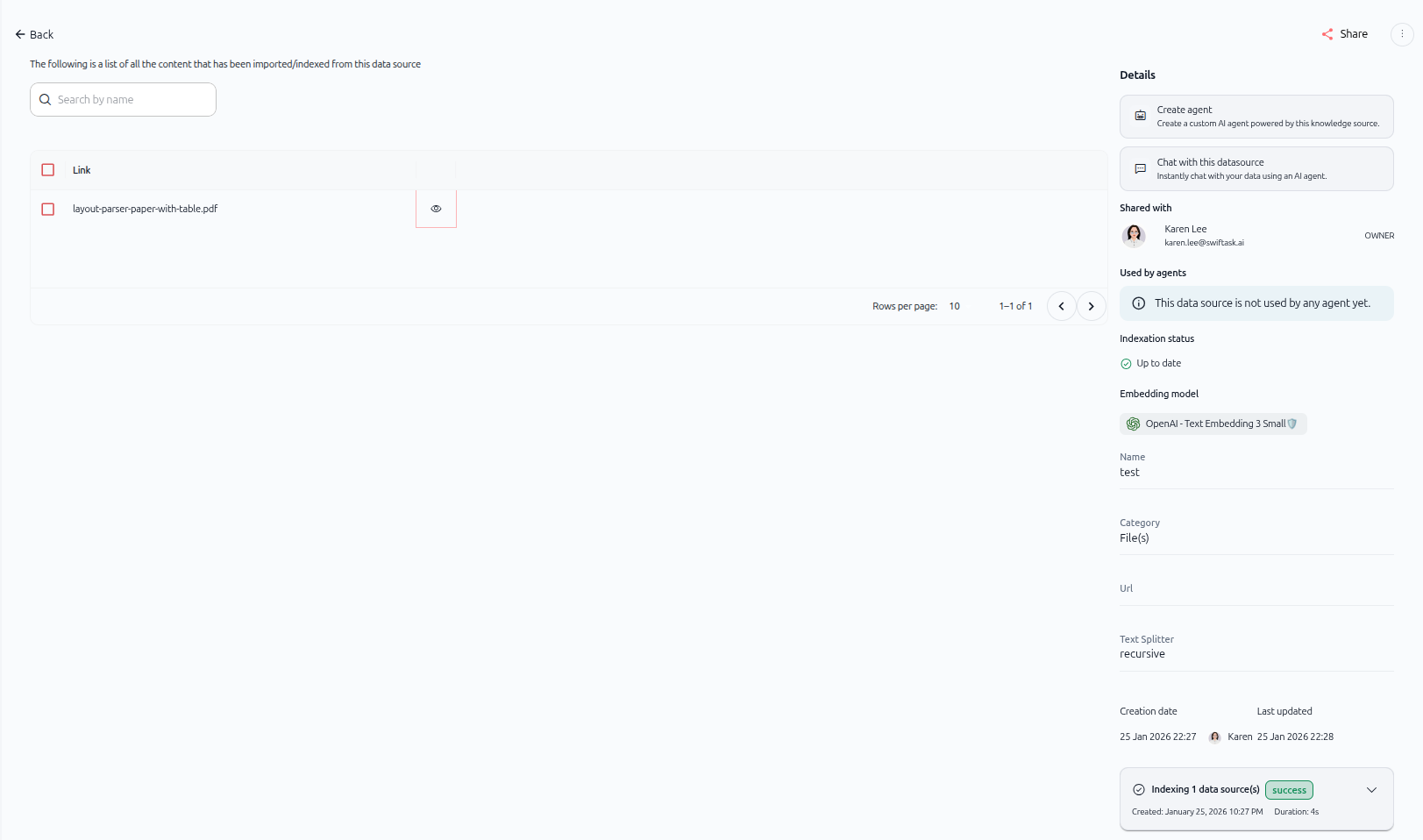
As shown in the image above, the imported data source displays:
Left panel: Content list
A list of all content imported from this data source
Search bar to find specific items by name
Each item shows a checkbox and an eye icon for viewing details
Right panel: Details
Create agent – Create a custom AI agent powered by this knowledge source
Chat with this datasource – Instantly chat with your data using an AI agent
Shared with – Shows who has access (e.g., "Karen Lee" as OWNER)
Used by agents – Lists agents using this data source (or "This data source is not used by any agent yet")
Indexation status – Shows "Up to date" when indexing is complete
Embedding model – Displays the model used (e.g., "OpenAI - Text Embedding 3 Small")
Name – The data source name (e.g., "test")
Category – Shows the type (e.g., "File(s)")
Url – Displays the source URL if applicable
Text Splitter – Shows the splitting method used (e.g., "recursive")
Creation date and Last updated – Timestamps for tracking changes
Indexing status – Expandable section showing indexing progress (e.g., "Indexing 1 data source(s): success")
8. Preview document content (optional)
To preview the extracted content from your document, click the eye icon next to any item in the content list.
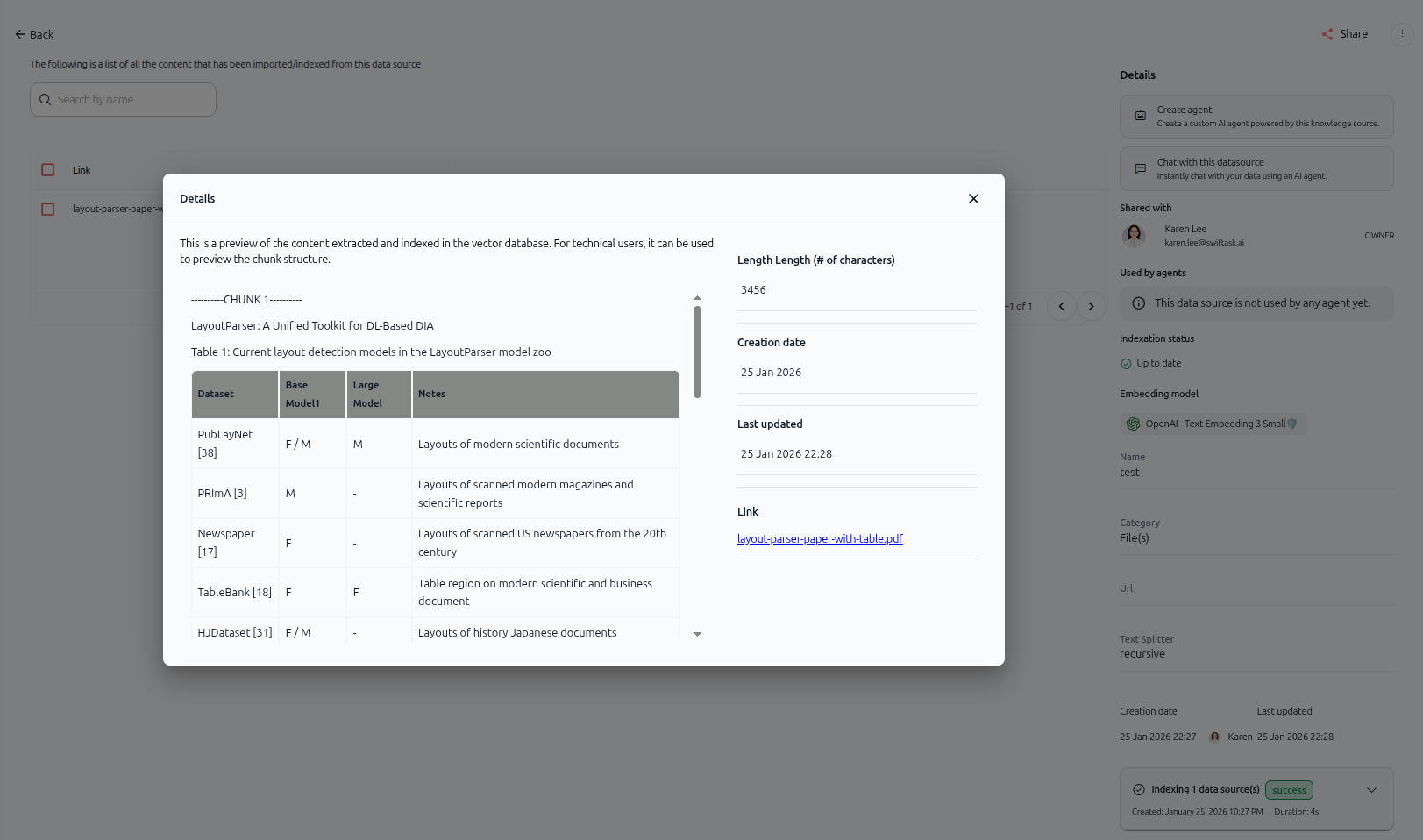
As shown in the image above, a Details modal opens displaying:
Left section: Extracted content preview
A preview of the content extracted and indexed in the vector database
Technical note: "This is a preview of the content extracted and indexed in the vector database. For technical users, it can be used to preview the chunk structure."
The actual text content from your document, showing how it was chunked (e.g., "----------CHUNK 1----------" followed by the extracted text)
Right section: Metadata
Length – Number of characters in the chunk (e.g., "3456")
Creation date – When the chunk was created (e.g., "25 Jan 2026")
Last updated – When the chunk was last modified (e.g., "25 Jan 2026 22:28")
Link – A clickable link to the original file (e.g., "layout-parser-paper-with-table.pdf")
This preview helps you verify that Swiftask correctly extracted and processed your document content.
How file processing works
Automatic OCR and text extraction
When you upload a PDF or image, Swiftask automatically extracts text using Mistral OCR technology. This means:
PDFs: All text content is extracted, whether the PDF is text-based or scanned
Images: Text embedded in screenshots, photos, or scanned documents is automatically extracted
No manual steps needed: Extraction happens automatically in the background
Document parsing
Swiftask parses your files to understand their structure and content:
Documents (DOCX, TXT, PDF): Text is extracted and analyzed
Spreadsheets (CSV, XLSX): Rows, columns, and data relationships are recognized
Data files (JSON, XML): Structured data is parsed and made available for queries
Code files: Code structure and syntax are preserved
Chunking and embedding
Your documents are split into chunks and converted into vector embeddings:
Chunking: Content is divided into smaller pieces based on your chunk size setting (default: 1024 tokens)
Embedding: Each chunk is converted into a vector representation using the selected embedding model
Indexing: Vectors are stored in a searchable database that agents can query
Practical use cases
Build an HR knowledge base
Upload employee handbooks, policies, and benefits documentation. Create an HR agent that answers employee questions using your actual policies.
Centralize product documentation
Upload product manuals, troubleshooting guides, and FAQs. Build a technical support agent that provides accurate answers based on your documentation.
Organize research and reports
Upload market research, competitor analysis, and internal reports. Create a research agent that analyzes data and generates insights.
Store legal and compliance documents
Upload contracts, compliance guidelines, and legal policies. Build an agent that references specific clauses and regulations.
Tips & best practices
Use clear, descriptive names: Name your data sources clearly so you can identify them later. Instead of "Document 1," use "HR Hiring Standards 2025" or "Product Manual v3.2."
Organize with folders: Group related documents in folders to keep your knowledge base organized.
Keep chunk size at default (1024): The default chunk size works well for most use cases. Adjust only if you have specific retrieval needs.
Add metadata for context: Use the metadata field to add context that helps AI understand your documents better.
Update sources regularly: If your documentation changes, re-upload or replace the data source. Outdated information leads to incorrect agent responses.
Test after importing: After importing, test your agents by asking questions that should reference the new content. Verify accuracy.
Troubleshooting
File didn't upload
Cause: File format not supported or file size exceeds limit
Solution:
Check that your file is one of the supported types (PDF, DOCX, XLSX, CSV, TXT, JSON, etc.)
Verify the file is within your plan's size limit
Try again with a different file
Text wasn't extracted correctly
Cause: Poor image quality or corrupted file
Solution:
Ensure scanned documents are clear and high-resolution
Try re-saving the file in a different format
Contact support if the issue persists
Indexing failed
Cause: Processing error or insufficient credits
Solution:
Check your credit balance in Settings → Usage & Billing
Retry the upload
Contact support if the error continues
Agent can't find information
Cause: Content not properly indexed or chunk size too large
Solution:
Verify the indexation status shows "Up to date"
Try reducing chunk size for more granular retrieval
Check that the agent is connected to the correct data source
What happens next
Once you've imported your documents, you're ready to:
Create an agent – Build a custom AI agent powered by your knowledge source
Chat with your data – Use the "Chat with this datasource" feature to instantly query your documents
Share with teammates – Give team members access to your knowledge base
Connect to agents – Link your data source to existing agents to enhance their capabilities
Your documents are now indexed, searchable, and ready to power AI-driven workflows across your workspace.
Additional resources
Knowledge base – Introduction – Learn what knowledge base is and why it matters
Import website and web pages – Add web content to your knowledge base
Import from Google Drive – Sync files from cloud storage
Permissions and access – Control who can see and use your knowledge base
Creating an agent – Build an agent and connect it to your knowledge base
Ready to import your first documents? Click Knowledge in the sidebar, then Import → Import from my computer. Select your files, configure your settings, and let Swiftask handle the rest.