Importer des documents / fichiers
Écrit par Stanislas
Dernière mise à jour Il y a 6 mois
Téléversez des fichiers depuis votre ordinateur pour constituer votre base de connaissances. Swiftask extrait automatiquement le texte des documents grâce à la technologie OCR, les découpe en segments interrogeables et les rend accessibles aux agents IA et aux membres de votre espace de travail.
Que vous ayez besoin de téléverser des PDF, des documents Word, des tableurs ou des fichiers de code, l'import de fichiers facilite la centralisation des connaissances de votre organisation en un seul endroit. Importez une fois, utilisez partout — dans le Chat, les Agents et les Projets.
Présentation
La fonction d'import de documents vous permet de téléverser des fichiers directement depuis votre ordinateur vers votre base de connaissances. Swiftask traite automatiquement vos fichiers, en extrayant le texte des images et des PDF grâce à la technologie OCR Mistral, en analysant les données structurées et en indexant le tout pour une recherche et une récupération instantanées alimentées par l'IA.
Vous pouvez téléverser plusieurs types de fichiers, y compris des documents (PDF, DOCX, TXT), des tableurs (CSV, XLSX), des fichiers de code (JSON, MD, etc.) et plus encore. Chaque fichier est traité, découpé en segments et stocké en tant que source de données accessible par les agents et les membres de l'équipe.
Prérequis
Pour importer des documents dans votre base de connaissances, vous avez besoin :
D'un compte Swiftask (inscrivez-vous sur swiftask.ai)
Accès à la section Connaissances
Des fichiers sur votre ordinateur (formats pris en charge : PDF, DOCX, XLSX, CSV, TXT, JSON, fichiers de code, etc.)
Autorisation de créer des sources de données dans votre espace de travail
L'importation de fichiers est disponible pour tous les utilisateurs Swiftask.
Types de fichiers pris en charge
Swiftask accepte un large éventail de formats de fichiers :
Documents : PDF, DOCX, DOC, TXT
Feuilles de calcul : XLSX, XLS, CSV
Formats de données : JSON, XML, MD
Fichiers de code : Python, JavaScript et autres fichiers de langage de programmation
Taille des fichiers : consultez les limites de votre plan pour la taille maximale par téléversement.
Guide étape par étape
1. Accédez à Connaissances
Cliquez sur Connaissances dans la barre latérale gauche. Vous verrez l'interface Connaissances avec toutes vos sources de données et tous vos dossiers.
2. Cliquez sur le bouton Importer
Dans la section Connaissances, recherchez et cliquez sur le bouton Importer. Un menu déroulant apparaît avec plusieurs options d'importation.
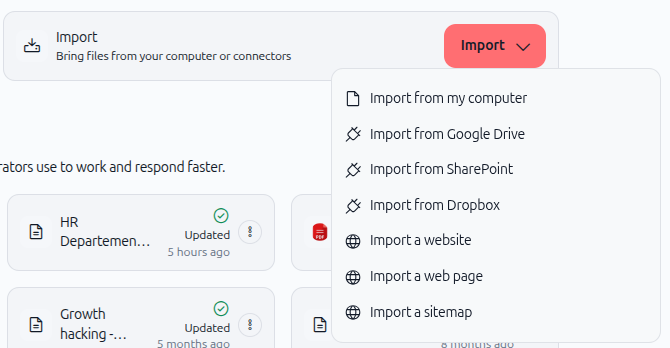
Comme le montre l'image ci-dessus, plusieurs options d'importation s'offrent à vous :
Importer depuis mon ordinateur : télévesez des fichiers directement depuis votre appareil.
Importer depuis Google Drive – Synchronisez les fichiers depuis Google Drive
Importer depuis SharePoint – Connectez-vous aux documents SharePoint
Importer depuis Dropbox – Synchroniser les fichiers depuis Dropbox
Importer un site web – Extraire le contenu d'un site web
Importer une page web – Importez une seule page web
Importer un plan du site – Importer plusieurs pages à partir d'un plan du site
Pour ce guide, sélectionnez Importer depuis mon ordinateur.
3. Configurez l'importation de vos fichiers
L'écran de configuration de l'importation de fichiers s'ouvre. C'est ici que vous téléverserez vos fichiers et configurer la manière dont Swiftask les traite.
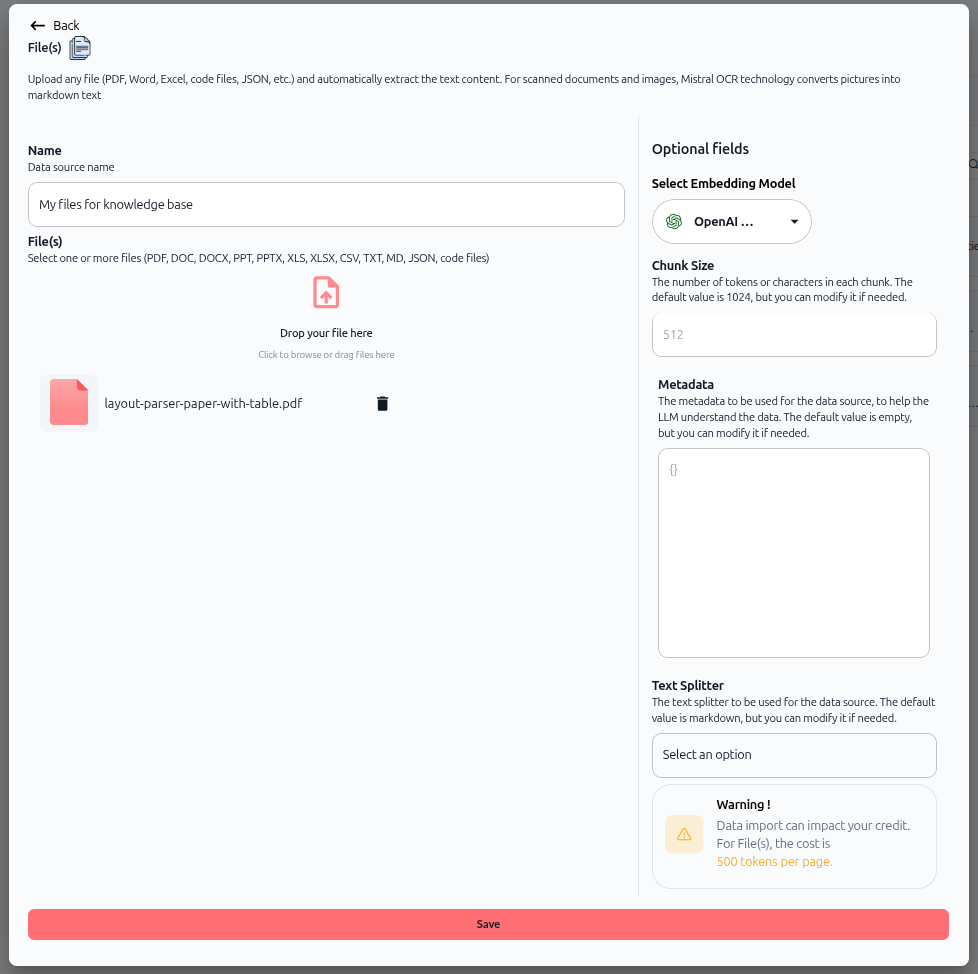
Comme le montre l'image ci-dessus, l'écran est divisé en deux sections :
Section de gauche : Téléversement de fichiers
Nom – Entrez un nom descriptif pour votre source de données (par exemple, « Mes fichiers pour la base de connaissances »).
Fichier(s) – Déposez vos fichiers ici ou cliquez pour les parcourir. Vous pouvez sélectionner un ou plusieurs fichiers (PDF, DOC, DOCX, PPT, PPTX, XLS, XLSX, CSV, TXT, MD, JSON, fichiers de code)
Section de droite : champs facultatifs
Sélectionner le modèle d'intégration – Choisissez le modèle d'IA utilisé pour créer des intégrations vectorielles de votre contenu (par défaut : OpenAI Text Embedding 3 Small). Cela détermine la manière dont votre contenu est indexé et recherché
Taille des blocs – Définissez le nombre de tokens ou de caractères dans chaque bloc. La valeur par défaut est 512, mais vous pouvez la modifier si nécessaire. Les blocs plus petits permettent une recherche plus précise ; les blocs plus grands fournissent plus de contexte
Métadonnées : ajoutez des métadonnées personnalisées au format JSON pour aider l'IA à comprendre vos données. Ce champ est facultatif, mais utile pour ajouter du contexte
Séparateur de texte – Choisissez la méthode de séparation du contenu textuel. La valeur par défaut est markdown, mais vous pouvez sélectionner d'autres options dans le menu déroulant.
Avertissement ! – Un indicateur de coût affiche la consommation de crédits : « Pour les fichiers, le coût est de 500 jetons par page ».
L'écran mentionne également que Swiftask utilise la technologie OCR Mistral pour convertir les documents et images numérisés en texte markdown.
4. Téléverser vos fichiers
Option 1 : glisser-déposer
Faites glisser les fichiers depuis votre ordinateur directement dans la zone « Déposez votre fichier ici ».
Option 2 : Parcourir et sélectionner
Cliquez sur « Cliquez pour parcourir ou glisser-déposer des fichiers ici », puis sélectionnez les fichiers dans votre système de fichiers.
Vous pouvez téléverser plusieurs fichiers à la fois. Chaque fichier apparaît dans la zone de téléversement avec son nom et une icône de suppression (corbeille) si vous devez le supprimer.
5. Configurez les paramètres facultatifs (si nécessaire)
Modèle d'intégration : laissez le paramètre par défaut (OpenAI Text Embedding 3 Small) sauf si vous avez des exigences spécifiques.
Taille des blocs : conservez la valeur par défaut (512) pour la plupart des cas d'utilisation. Ne la modifiez que si vous avez besoin d'une récupération de contexte plus granulaire ou plus large.
Métadonnées : ajoutez des métadonnées personnalisées si vous souhaitez fournir un contexte supplémentaire à l'IA. Par exemple :
{ "department": "HR", "year": "2025", "document_type": "policy" } Séparateur de texte : conservez la valeur par défaut (markdown) sauf si votre document nécessite une méthode de séparation spécifique.
6. Enregistrer et traiter
Une fois vos fichiers téléversés et configurés, cliquez sur le bouton Enregistrer en bas de l'écran.
Swiftask traite vos fichiers en arrière-plan :
Le texte est extrait des PDF et des images à l'aide de la reconnaissance optique de caractères (OCR).
Le contenu est divisé en morceaux en fonction de la taille de morceau que vous avez définie
Les segments sont intégrés à l'aide du modèle d'intégration sélectionné
La source de données est indexée et rendue consultable
Un indicateur de progression s'affiche. Une fois le processus terminé, votre source de données apparaît dans la section Connaissances.
7. Affichez vos documents importés
Après le traitement, retournez à la section Connaissances. Votre nouvelle source de données apparaît dans la liste.
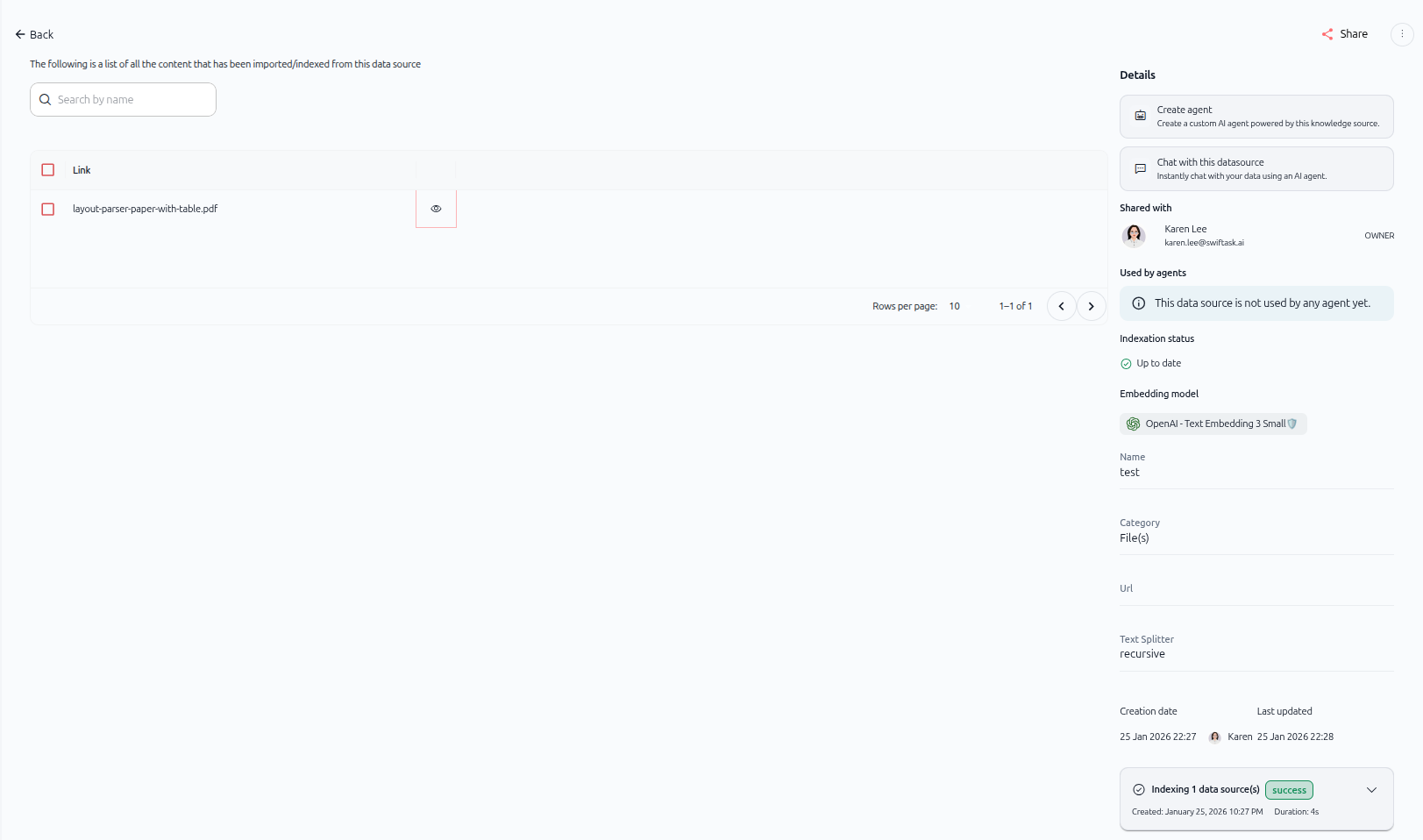
Comme le montre l'image ci-dessus, la source de données importée affiche :
Panneau de gauche : liste du contenu
Une liste de tout le contenu importé à partir de cette source de données
Barre de recherche pour trouver des éléments spécifiques par nom
Chaque élément est accompagné d'une case à cocher et d'une icône en forme d'œil permettant d'afficher les détails
Panneau de droite : Détails
Créer un agent – Créez un agent IA personnalisé alimenté par cette source de connaissances
Discuter avec cette source de données – Discutez instantanément avec vos données à l'aide d'un agent IA
Partagé avec : indique qui a accès (par exemple, « Karen Lee » en tant que PROPRIÉTAIRE)
Utilisé par les agents : répertorie les agents qui utilisent cette source de données (ou « Cette source de données n'est encore utilisée par aucun agent »)
Statut d'indexation – Affiche « À jour » lorsque l'indexation est terminée
Modèle d'intégration – Affiche le modèle utilisé (par exemple, « OpenAI - Text Embedding 3 Small »)
Nom – Nom de la source de données (par exemple, « test »)
Catégorie – Indique le type (par exemple, « Fichier(s) »)
URL – Affiche l'URL source, le cas échéant
Séparateur de texte – Affiche la méthode de séparation utilisée (par exemple, « récursive »)
Date de création et dernière mise à jour – Horodatages permettant de suivre les modifications
État de l'indexation – Section extensible indiquant la progression de l'indexation (par exemple, « Indexation de 1 source(s) de données : réussite »)
8. Prévisualiser le contenu du document (facultatif)
Pour prévisualiser le contenu extrait de votre document, cliquez sur l'icône en forme d'œil à côté de n'importe quel élément de la liste de contenu.
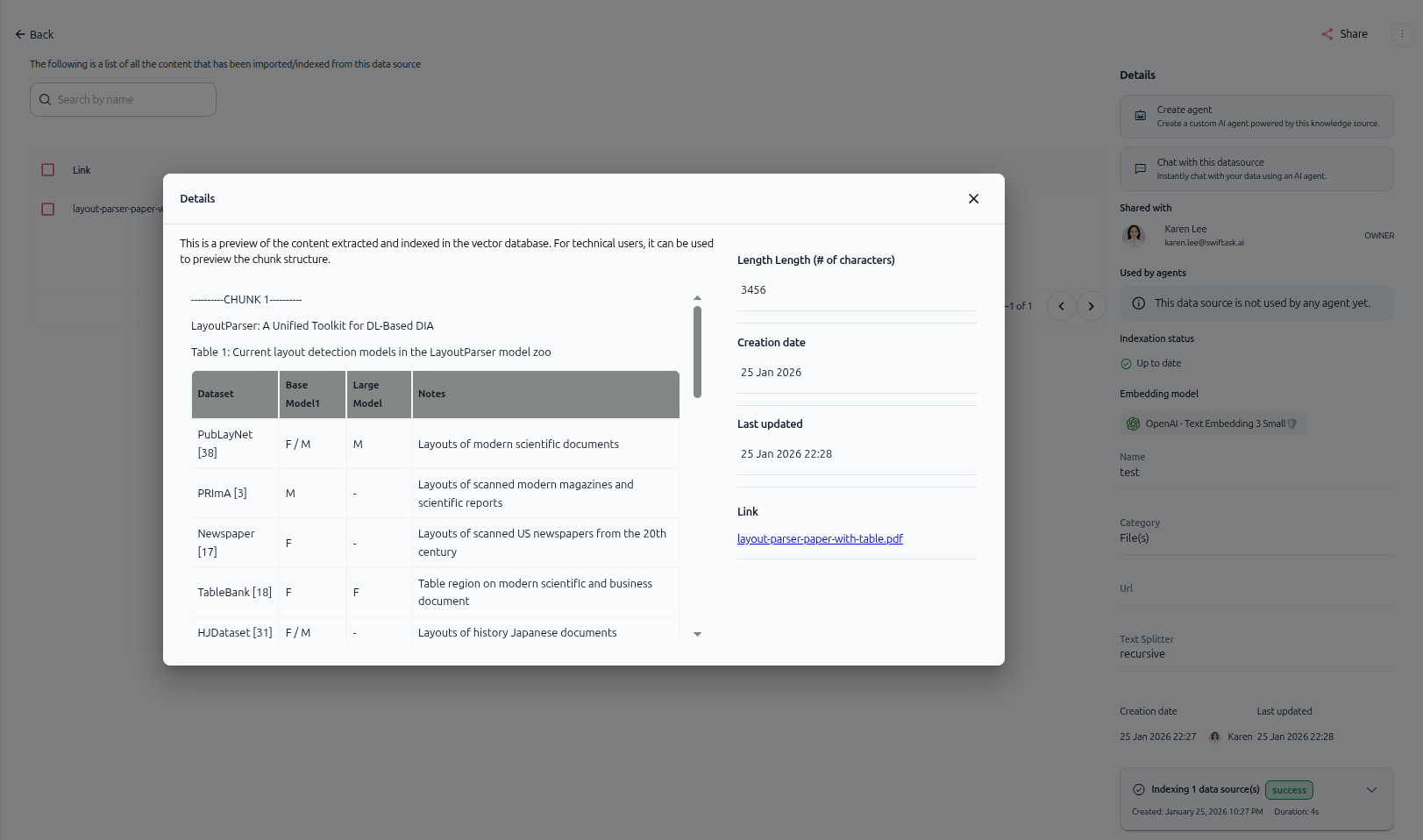
Comme le montre l'image ci-dessus, une fenêtre modale Détails s'ouvre et affiche :
Section de gauche : aperçu du contenu extrait
Aperçu du contenu extrait et indexé dans la base de données vectorielle
Note technique : « Il s'agit d'un aperçu du contenu extrait et indexé dans la base de données vectorielle. Pour les utilisateurs techniques, il peut être utilisé pour prévisualiser la structure des blocs. »
Le contenu textuel réel de votre document, montrant comment il a été fragmenté (par exemple, « ----------CHUNK 1---------- » suivi du texte extrait)
Section droite : métadonnées
Longueur – Nombre de caractères dans le bloc (par exemple, « 3456 »)
Date de création – Date à laquelle le fragment a été créé (par exemple, « 25 janvier 2026 »)
Dernière mise à jour – Date de la dernière modification du fragment (par exemple, « 25 janvier 2026 22:28 »)
Lien – Lien cliquable vers le fichier d'origine (par exemple, « layout-parser-paper-with-table.pdf »)
Cet aperçu vous aide à vérifier que Swiftask a correctement extrait et traité le contenu de votre document.
Fonctionnement du traitement des fichiers
Extraction automatique de texte par OCR
Lorsque vous téléversez un fichier PDF ou une image, Swiftask extrait automatiquement le texte à l'aide de la technologie OCR Mistral. Cela signifie que :
PDF : tout le contenu textuel est extrait, que le PDF soit basé sur du texte ou numérisé
Images : le texte intégré dans les captures d'écran, les photos ou les documents numérisés est automatiquement extrait
Aucune étape manuelle n'est nécessaire : l'extraction se fait automatiquement en arrière-plan
Analyse des documents
Swiftask analyse vos fichiers pour comprendre leur structure et leur contenu :
Documents (DOCX, TXT, PDF) : le texte est extrait et analysé
Feuilles de calcul (CSV, XLSX) : les lignes, les colonnes et les relations entre les données sont reconnues
Fichiers de données (JSON, XML) : les données structurées sont analysées et mises à disposition pour les requêtes
Fichiers de code : la structure et la syntaxe du code sont conservées
Découpage et intégration
Vos documents sont divisés en morceaux et convertis en intégrations vectorielles :
Découpage : le contenu est divisé en morceaux plus petits en fonction de votre paramètre de taille de morceau (par défaut : 1024 tokens)
Intégration : chaque morceau est converti en une représentation vectorielle à l'aide du modèle d'intégration sélectionné
Indexation : les vecteurs sont stockés dans une base de données consultable que les agents peuvent interroger
Cas d'utilisation pratiques
Construisez une base de connaissances RH
Téléversez les manuels, les politiques et les documents relatifs aux avantages sociaux des employés. Créez un agent RH qui répond aux questions des employés en utilisant vos politiques réelles.
Centraliser la documentation sur les produits
Téléversez les manuels des produits, les guides de dépannage et les FAQ. Créez un agent d'assistance technique qui fournit des réponses précises basées sur votre documentation.
Organisez vos recherches et vos rapports
Téléversez les études de marché, les analyses de la concurrence et les rapports internes. Créez un agent de recherche qui analyse les données et génère des informations.
Stockez les documents juridiques et de conformité
Téléversez les contrats, les directives de conformité et les politiques juridiques. Créez un agent qui fait référence à des clauses et réglementations spécifiques.
Conseils et bonnes pratiques
Utilisez des noms clairs et descriptifs : nommez clairement vos sources de données afin de pouvoir les identifier ultérieurement. Au lieu de « Document 1 », utilisez « Normes d'embauche RH 2025 » ou « Manuel du produit v3.2 ».
Organisez vos données à l'aide de dossiers : regroupez les documents connexes dans des dossiers afin de maintenir votre base de connaissances organisée.
Conservez la taille de bloc par défaut (1024) : la taille de bloc par défaut convient à la plupart des cas d'utilisation. Ne la modifiez que si vous avez des besoins spécifiques en matière de récupération.
Ajoutez des métadonnées pour le contexte : utilisez le champ des métadonnées pour ajouter du contexte qui aide l'IA à mieux comprendre vos documents.
Mettez régulièrement à jour les sources : si votre documentation change, téléversez à nouveau ou remplacez la source de données. Des informations obsolètes entraînent des réponses incorrectes de la part des agents.
Testez après l'importation : après l'importation, testez vos agents en leur posant des questions qui font référence au nouveau contenu. Vérifiez l'exactitude des réponses.
Dépannage
Le fichier n'a pas été téléversez
Cause : format de fichier non pris en charge ou taille du fichier supérieure à la limite
Solution
Vérifiez que votre fichier est l'un des types pris en charge (PDF, DOCX, XLSX, CSV, TXT, JSON, etc.)
Vérifiez que la taille du fichier respecte la limite fixée par votre forfait
Réessayez avec un autre fichier
Le texte n'a pas été extrait correctement
Cause : mauvaise qualité de l'image ou fichier corrompu.
Solution :
Assurez-vous que les documents numérisés sont clairs et en haute résolution
Essayez de réenregistrer le fichier dans un autre format
Contactez l'assistance si le problème persiste
Échec de l'indexation
Cause : erreur de traitement ou crédits insuffisants
Solution :
Vérifiez votre solde de crédits dans Paramètres → Utilisation et facturation
Réessayez le Téléversement
Contactez l'assistance si l'erreur persiste
L'agent ne trouve pas les informations
Cause : contenu mal indexé ou taille des blocs trop importante
Solution :
Vérifiez que le statut d'indexation indique « À jour »
Essayez de réduire la taille des blocs pour obtenir une récupération plus granulaire
Vérifiez que l'agent est connecté à la bonne source de données
Étapes suivantes
Une fois vos documents importés, vous êtes prêt à :
Créer un agent – Créez un agent IA personnalisé alimenté par votre source de connaissances
Discuter avec vos données : utilisez la fonctionnalité « Discuter avec cette source de données » pour interroger instantanément vos documents
Partager avec vos coéquipiers : donnez aux membres de votre équipe accès à votre base de connaissances
Connecter des agents : reliez votre source de données à des agents existants pour améliorer leurs capacités
Vos documents sont désormais indexés, consultables et prêts à alimenter des workflows basés sur l'IA dans votre espace de travail.
Ressources supplémentaires
Base de connaissances – Introduction – Découvrez ce qu'est une base de connaissances et pourquoi elle est importante
Importer un site web et des pages web – Ajoutez du contenu web à votre base de connaissances
Importer depuis Google Drive – Synchronisez des fichiers depuis le stockage cloud
Autorisations et accès – Contrôlez qui peut voir et utiliser votre base de connaissances
Création d'un agent – Créez un agent et connectez-le à votre base de connaissances
Prêt à importer vos premiers documents ? Cliquez sur Connaissances dans la barre latérale, puis sur Importer → Importer depuis mon ordinateur. Sélectionnez vos fichiers, configurez vos paramètres et laissez Swiftask s'occuper du reste.