Importer un Site web / page web
Écrit par Stanislas
Dernière mise à jour Il y a 6 mois
Ajoutez du contenu web à votre base de connaissances pour que les agents IA puissent accéder aux informations des sites web et s'y référer. Swiftask extrait, traite et indexe automatiquement le contenu web, le rendant consultable et disponible pour les agents dans votre espace de travail.
Que vous ayez besoin d'importer une seule page web ou un site entier avec de multiples pages, Swiftask gère automatiquement l'extraction et l'indexation. Importez une fois, et vos agents pourront instantanément faire référence au contenu pour répondre aux questions ou accomplir des tâches.
Aperçu
La fonctionnalité d'import de site web et de page web vous permet d'ajouter du contenu web directement à votre base de connaissances. Swiftask extrait automatiquement le contenu, le traite en fragments consultables et indexe le tout pour une recherche et une récupération instantanées par IA.
Vous pouvez importer deux types de contenu web :
Site web – Importez plusieurs pages d'un site web en scannant et en suivant automatiquement les liens.
Page web – Importez le contenu d'une URL de page web spécifique et unique.
Chaque import crée une source de données dans votre base de connaissances, accessible par les agents et les membres de l'équipe. Vos agents utilisent ce contenu web pour fournir des réponses précises et à jour basées sur les informations que vous avez importées.
Comprendre la différence
Import de site web :
Extrait le contenu de plusieurs pages d'un site web.
Suit automatiquement les liens pour découvrir et importer les pages associées.
Idéal pour importer des sites de documentation, des blogs ou des sections entières d'un site web.
Vous permet de contrôler la profondeur et la portée du crawl.
Import de page web :
Extrait le contenu d'une seule page web.
Importe uniquement l'URL spécifique que vous fournissez.
Idéal pour importer des articles spécifiques, des pages produits ou des documents individuels.
Plus rapide et plus précis lorsque vous avez besoin d'un contenu spécifique.
Prérequis
Pour importer du contenu web dans votre base de connaissances, vous avez besoin de :
Un compte Swiftask (inscrivez-vous sur swiftask.ai)
Un accès à la section Connaissances
L'URL du site web ou de la page web que vous souhaitez importer
L'autorisation de créer des sources de données dans votre espace de travail
L'import de contenu web est disponible pour tous les utilisateurs de Swiftask.
Guide étape par étape
1. Accédez à Connaissances
Cliquez sur Connaissances dans la barre latérale gauche. Vous verrez l'interface Connaissances avec toutes vos sources de données et dossiers.
2. Cliquez sur le bouton Importer
Dans la section Connaissances, localisez et cliquez sur le bouton Importer. Un menu déroulant apparaît avec plusieurs options d'import.
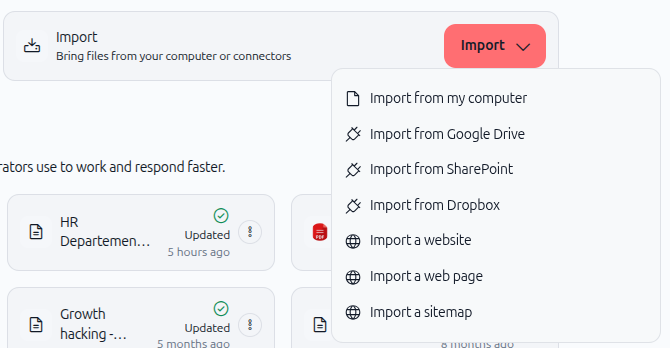
3. Choisissez votre type d'import
Sélectionnez soit Importer un site web soit Importer une page web selon vos besoins.
Importer un site web
Utilisez cette option lorsque vous souhaitez importer plusieurs pages d'un site web.
1. Sélectionnez "Importer un site web"
Dans le menu déroulant Importer, cliquez sur Importer un site web.
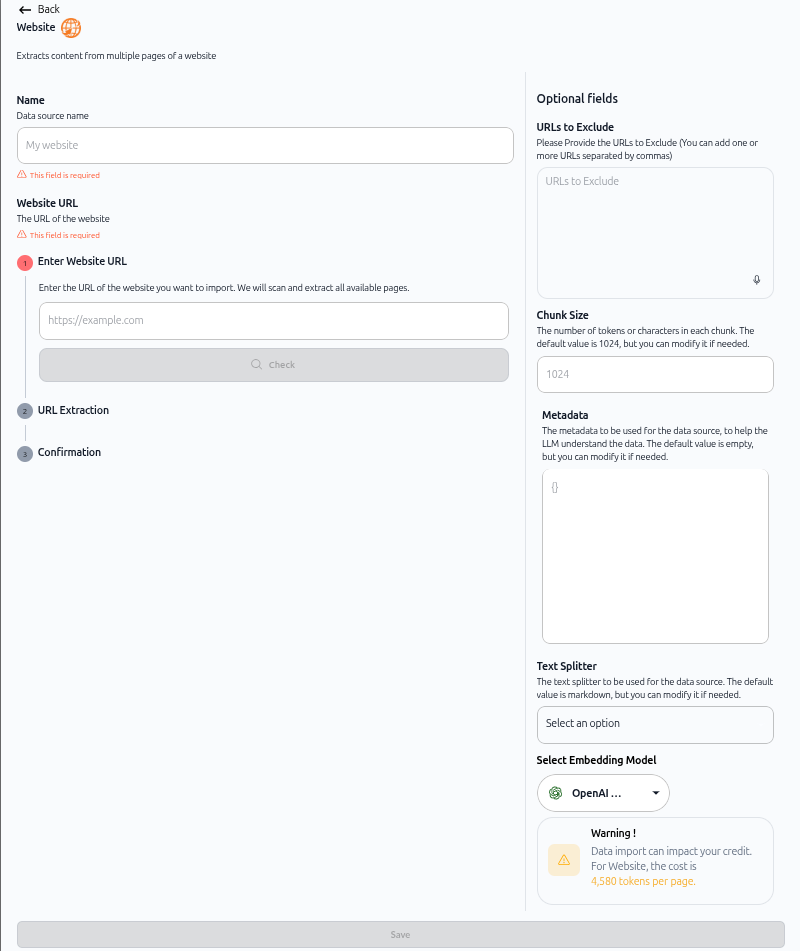
L'écran de configuration d'import de site web s'ouvre. Comme illustré ci-dessus, l'écran affiche :
Nom – Champ pour le nom de la source de données
URL du site web – L'URL du site web (indiquée comme obligatoire)
2. Saisissez les détails du site web
Champ Nom : Saisissez un nom descriptif pour votre source de données (ex. : "Wikipedia").
Champ URL du site web :
Saisissez l'URL complète du site web que vous voulez importer.
Incluez le protocole (
https://).Le champ indique qu'il est obligatoire.
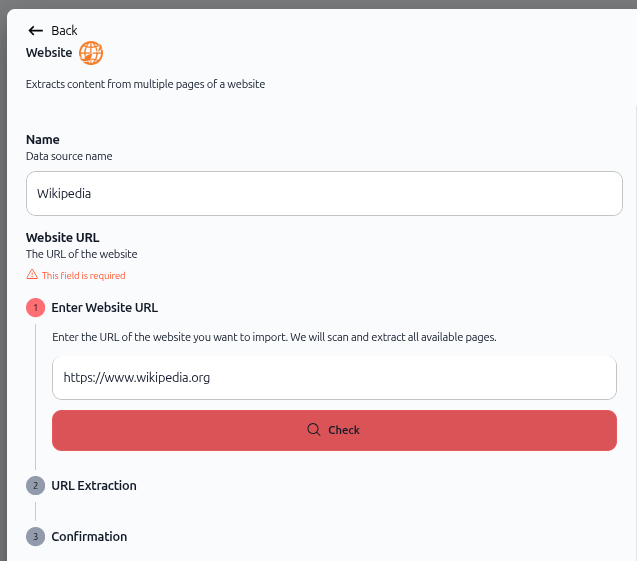
Exemple : https://www.wikipedia.org
3. Cliquez sur "Vérifier" pour valider l'URL
Après avoir saisi l'URL, cliquez sur le bouton Vérifier. Swiftask scanne le site web et découvre les pages disponibles.
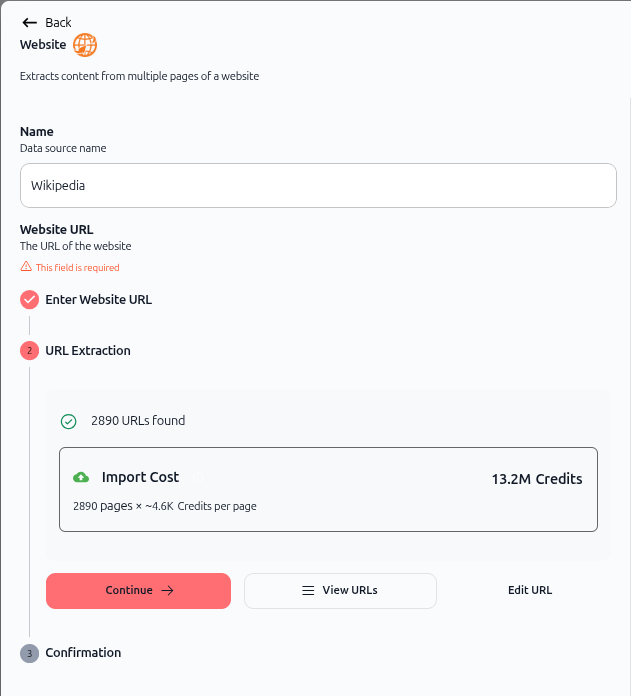
Comme illustré ci-dessus, une fois la validation terminée :
Une coche verte apparaît à côté de "Saisir l'URL du site web".
La section Extraction d'URL affiche le nombre de pages trouvées (ex. : "2890 pages trouvées").
Coût d'import montre la consommation de crédits estimée.
Le bouton Continuer devient disponible.
4. Examinez le coût d'import et les URL
L'écran affiche :
Coût d'import :
Estimation totale en crédits (ex. : "13,2M de Crédits")
Détail : "2890 pages × ~4,6K Crédits par page"
Actions optionnelles :
Voir les URL – Cliquez pour voir la liste des pages découvertes.
Modifier l'URL – Modifiez l'URL du site web si nécessaire.
5. Configurez les paramètres optionnels (si nécessaire)
Sur le côté droit de l'écran, vous trouverez des champs de configuration optionnels :
URL à exclure :
Saisissez les URL que vous souhaitez exclure de l'import.
Séparez plusieurs URL par des virgules.
Utile pour ignorer les sections non pertinentes.
Taille des fragments :
Le nombre de jetons ou caractères dans chaque fragment.
La valeur par défaut est 1024.
Modifiez si nécessaire pour votre cas d'usage.
Métadonnées :
Ajoutez des métadonnées personnalisées pour aider le LLM à comprendre les données.
La valeur par défaut est vide.
Modifiez si nécessaire.
Séparateur de texte :
Sélectionnez la méthode de découpage du texte.
Choisissez parmi les options du menu déroulant.
Sélectionner un modèle d'embedding :
Choisissez le modèle d'embedding (par défaut : OpenAI).
Un avertissement montre le coût : "Pour un Site web, le coût est de 4 580 tokens par page".
6. Cliquez sur "Continuer" et confirmez
Une fois que vous avez examiné les paramètres, cliquez sur le bouton Continuer.
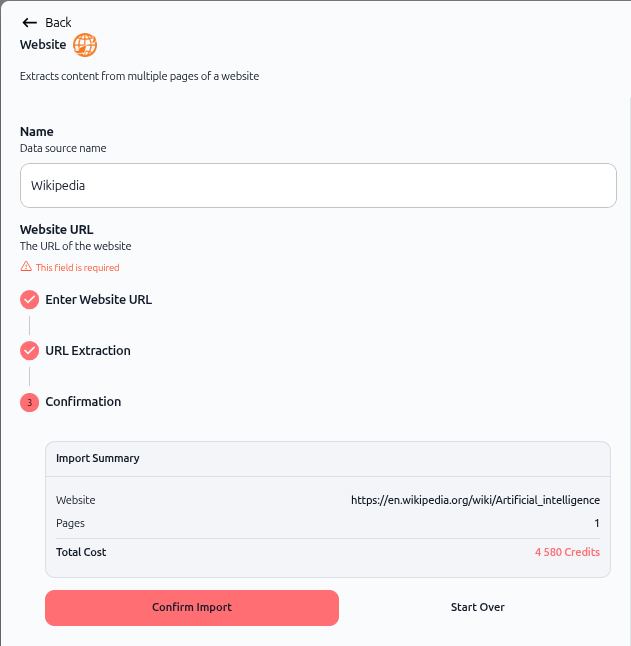
L'écran de confirmation affiche :
Résumé de l'import :
Site web : L'URL que vous importez
Pages : Nombre de pages (ex. : "1")
Coût total : Consommation de crédits (ex. : "4 580 Crédits")
Actions :
Confirmer l'import – Procéder à l'import
Recommencer – Annuler et redémarrer le processus
Cliquez sur Confirmer l'import et Enregistrer pour procéder.
7. Surveillez la progression de l'import
Swiftask traite le site web en arrière-plan :
Le contenu est extrait de chaque page découverte.
Le texte est découpé en fragments selon vos paramètres.
Les fragments sont vectorisés (embedding) à l'aide du modèle sélectionné.
La source de données est indexée et rendue consultable.
Vous verrez un indicateur de progression :
Icône de coche orange – Import en cours.
Icône de coche verte – Import terminé.
8. Consultez votre site web importé
Après le traitement, retournez à la section Connaissances. Votre nouvelle source de données apparaît dans la liste.
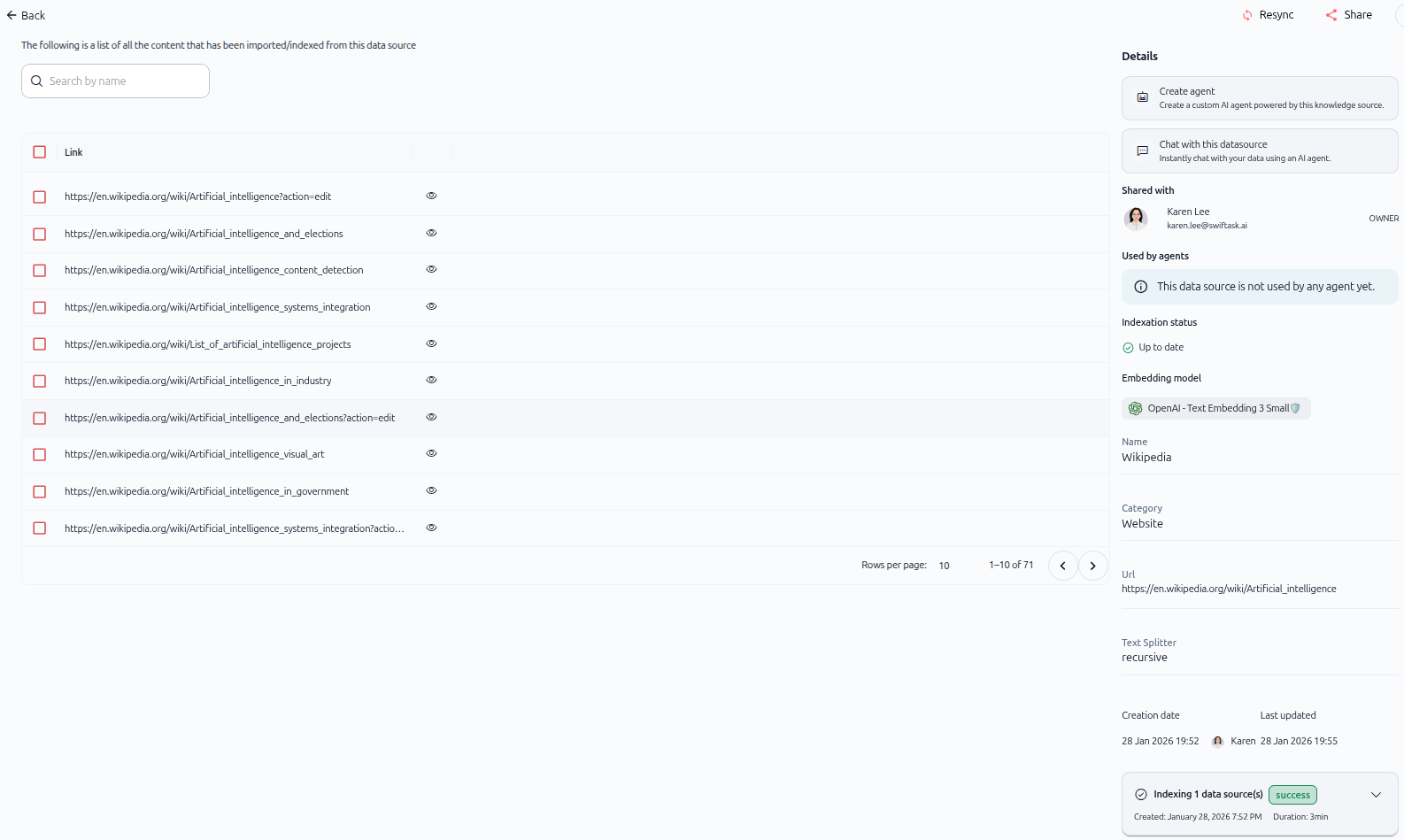
Comme illustré ci-dessus, la source de données importée affiche :
Panneau gauche : Liste du contenu
Une liste de toutes les pages importées du site web.
Une barre de recherche pour trouver des pages spécifiques par nom.
Chaque élément montre une case à cocher et une icône d'œil pour voir les détails.
Panneau droit : Détails
Créer un agent – Créez un agent IA personnalisé alimenté par cette source de connaissances.
Discuter avec cette source – Interrogez instantanément votre contenu web.
Partagé avec – Montre qui a accès (ex. : "Karen Lee - PROPRIÉTAIRE").
Utilisé par les agents – Liste les agents utilisant cette source de données.
Statut d'indexation – Affiche "À jour".
Modèle d'embedding – Affiche le modèle utilisé (ex. : "OpenAI - Text Embedding 3 Small").
Nom – Nom de la source de données (ex. : "Wikipedia").
Catégorie – Affiche "Site web".
Url – Affiche l'URL source.
Séparateur de texte – Affiche la méthode de découpage utilisée (ex. : "récursif").
Date de création et Dernière mise à jour – Horodatages pour suivre les modifications.
Statut d'indexation – Section extensible montrant la progression de l'indexation (ex. : "Indexation de 1 source(s) de données : succès").
Importer une page web
Utilisez cette option lorsque vous souhaitez importer le contenu d'une page web spécifique et unique.
1. Sélectionnez "Importer une page web"
Dans le menu déroulant Importer, cliquez sur Importer une page web.
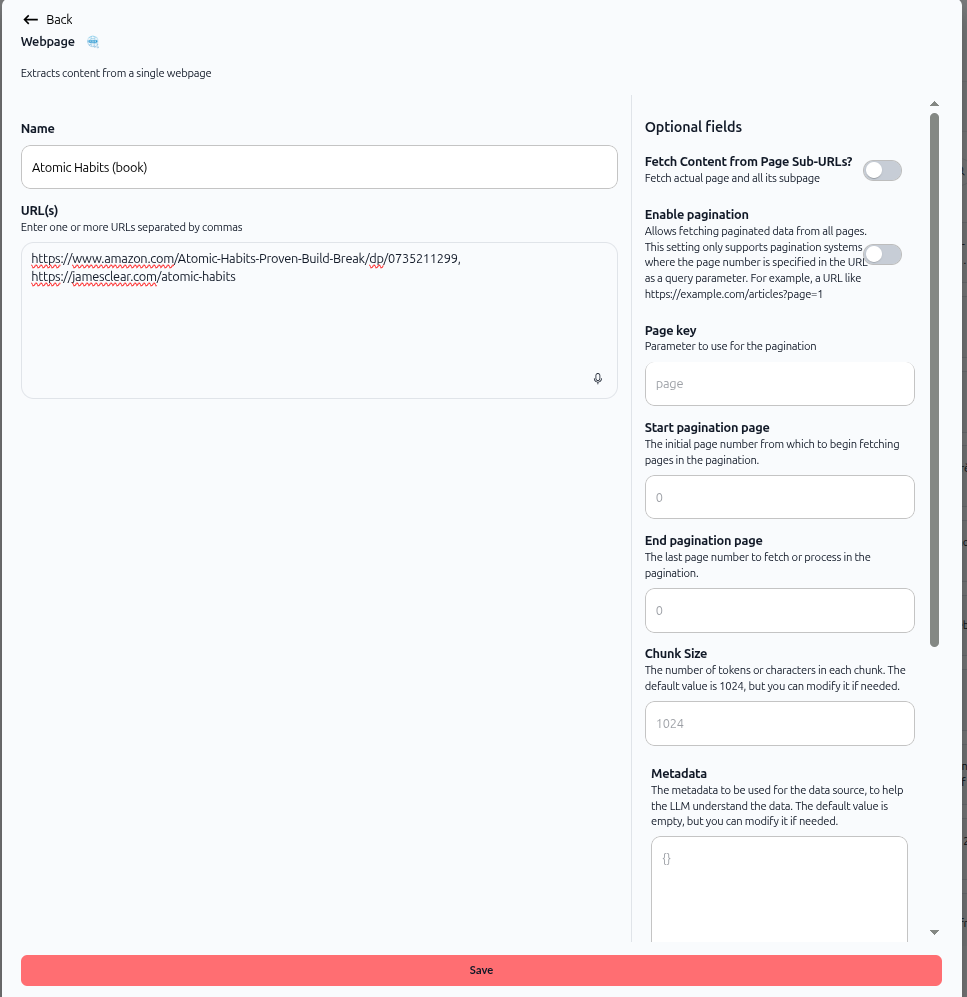
L'écran de configuration d'import de page web s'ouvre. Comme illustré ci-dessus, l'écran affiche :
Champs principaux :
Nom – Nom de la source de données.
URL(s) – Saisissez une ou plusieurs URL séparées par des virgules.
Champs optionnels (panneau droit) :
Récupérer le contenu des sous-URL de la page ? – Activez pour récupérer les sous-pages.
Activer la pagination – Pour le contenu paginé.
Clé de page – Paramètre à utiliser pour la pagination.
Page de pagination de départ – Numéro de page initial.
Page de pagination de fin – Dernier numéro de page.
Taille des fragments – Valeur par défaut 1024.
Métadonnées – Champ de métadonnées personnalisées.
Séparateur de texte – Choisissez la méthode de découpage.
Sélectionner un modèle d'embedding – Choisissez le modèle d'embedding.
2. Saisissez les détails de la page web
Champ Nom : Saisissez un nom descriptif pour votre source de données (ex. : "Atomic Habits (livre)").
Champ URL(s) : Saisissez l'URL complète (ou les URL) de la/des page(s) web que vous voulez importer. Vous pouvez saisir plusieurs URL séparées par des virgules.
Exemple :
https://www.amazon.com/Atomic-Habits-Proven-Build-Break/dp/0735211299, https://jamesclear.com/atomic-habits
3. Configurez les paramètres optionnels (si nécessaire)
Récupérer le contenu des sous-URL de la page :
Activez (ON) pour récupérer la page actuelle et toutes ses sous-pages.
Utile pour les pages avec du contenu lié.
Activer la pagination :
Activez (ON) pour le contenu paginé.
Permet de récupérer plusieurs pages dans les systèmes de pagination.
Spécifiez le paramètre d'URL (ex. : "page").
Paramètres de pagination :
Clé de page : Paramètre pour la pagination (ex. : "page").
Page de pagination de départ : Numéro de page initial (ex. : "0").
Page de pagination de fin : Dernier numéro de page à récupérer.
Taille des fragments :
Valeur par défaut 1024.
Modifiez si nécessaire.
Métadonnées :
Ajoutez des métadonnées personnalisées.
Valeur par défaut vide.
Séparateur de texte :
Sélectionnez la méthode de découpage dans le menu déroulant.
Sélectionner un modèle d'embedding :
Choisissez le modèle d'embedding (par défaut : OpenAI).
4. Cliquez sur "Enregistrer"
Une fois vos paramètres configurés, cliquez sur le bouton Enregistrer en bas de l'écran.
Swiftask traite la/les page(s) web en arrière-plan :
Le contenu est extrait de(s) URL spécifiée(s).
Le texte est découpé en fragments.
Les fragments sont vectorisés à l'aide du modèle sélectionné.
La source de données est indexée et rendue consultable.
5. Surveillez la progression de l'import
Vous verrez un indicateur de progression montrant le statut de l'import. Une fois terminé, le statut passe au vert avec un indicateur de succès.
6. Consultez votre page web importée
Après le traitement, retournez à la section Connaissances. Votre nouvelle source de données apparaît dans la liste.
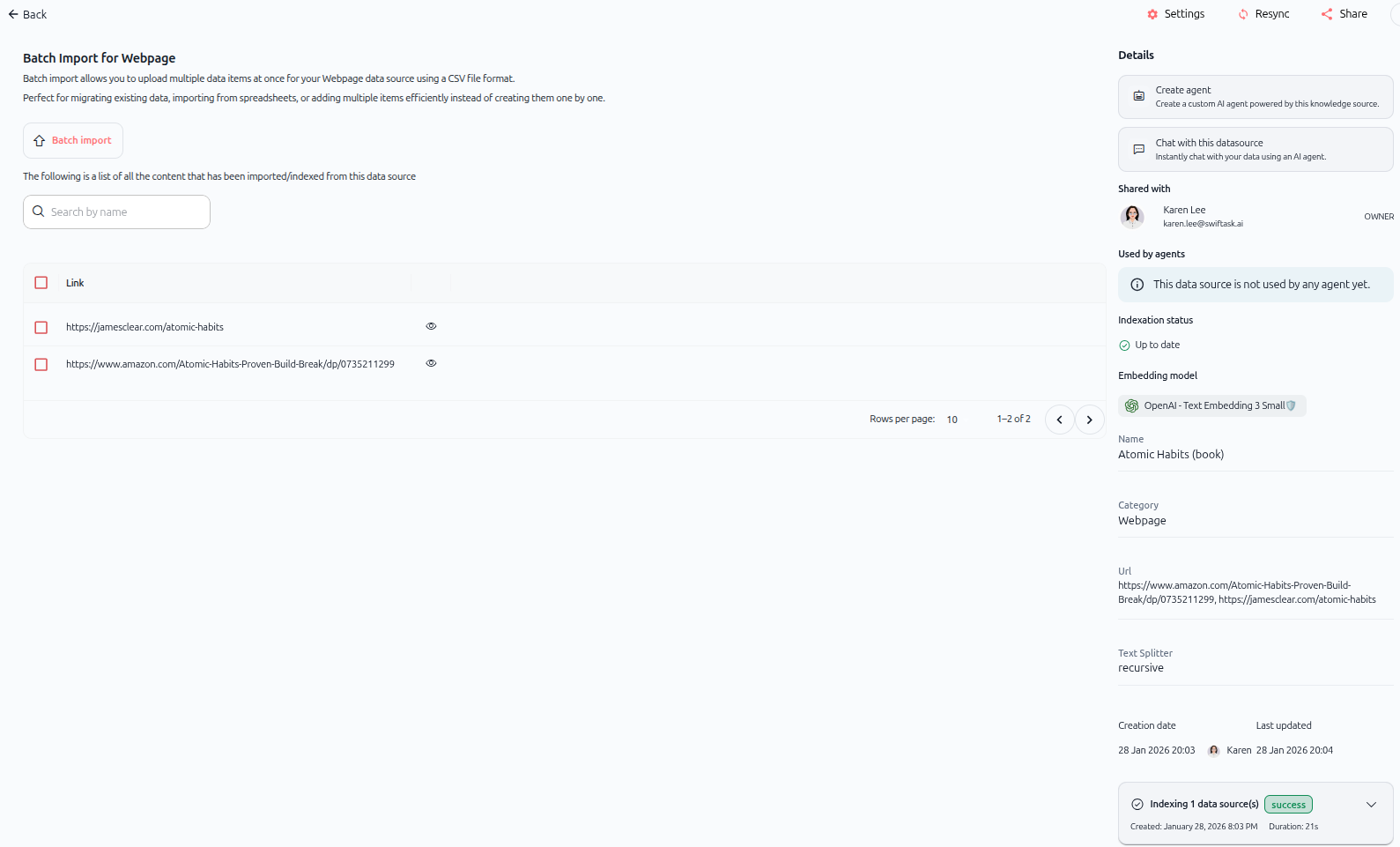
Comme illustré ci-dessus, la source de données importée affiche :
Panneau gauche : Liste du contenu
Une liste de tout le contenu importé de la/des page(s) web.
Chaque URL apparaît comme un élément séparé.
Icône d'œil pour voir les détails.
Panneau droit : Détails
Créer un agent – Créez un agent IA personnalisé.
Discuter avec cette source – Interrogez votre contenu instantanément.
Partagé avec – Informations de contrôle d'accès.
Utilisé par les agents – Montre quels agents utilisent ces données.
Statut d'indexation – Affiche "À jour".
Modèle d'embedding – Modèle utilisé pour l'embedding.
Nom – Nom de la source de données (ex. : "Atomic Habits (livre)").
Catégorie – Affiche "Page web".
Url – Affiche l'URL source (ou les URL).
Séparateur de texte – Méthode de découpage utilisée (ex. : "récursif").
Date de création et Dernière mise à jour – Horodatages.
Statut d'indexation – Indicateur de progression.
Cas d'usage pratiques
Importer la documentation produit : Importez le site web de documentation produit de votre entreprise. Votre agent support peut faire référence à des informations précises et à jour pour répondre aux questions des clients sur les fonctionnalités, le dépannage et les spécifications.
Importer des sites web concurrents : Importez des pages produits ou du contenu marketing de concurrents. Votre agent marketing peut analyser le positionnement, les fonctionnalités et le discours des concurrents pour éclairer votre stratégie.
Importer des actualités et recherches sectorielles : Importez des articles ou des documents de recherche spécifiques de sites web sectoriels. Votre agent de recherche peut faire référence aux dernières tendances, données et insights lors de la génération de rapports.
Importer le contenu d'un centre d'aide : Importez vos pages d'aide ou de FAQ. Votre agent support client peut fournir des réponses instantanées et précises basées sur votre documentation officielle.
Conseils & bonnes pratiques
Utilisez des noms descriptifs : Nommez clairement vos sources de données pour les identifier plus tard. Au lieu de "Site web 1", utilisez "Documentation Produit 2025" ou "Analyse Concurrent - SociétéX".
Commencez par des pages spécifiques : Si vous n'êtes pas sûr d'importer un site entier, commencez par un import de page web pour des URL spécifiques. Testez les résultats, puis étendez à l'import complet du site si nécessaire.
Excluez les pages non pertinentes : Utilisez le champ "URL à exclure" pour ignorer les pages comme les écrans de connexion, les paniers d'achat ou les pages de navigation qui ne contiennent pas de contenu utile.
Surveillez l'utilisation des crédits : Les imports de sites web peuvent consommer beaucoup de crédits selon le nombre de pages. Vérifiez l'estimation du coût d'import avant de confirmer.
Mettez à jour régulièrement : Le contenu web change fréquemment. Réimportez périodiquement vos sources de données pour maintenir les connaissances de vos agents à jour. Supprimez l'ancienne source et créez une nouvelle importation, ou utilisez la fonction de resynchronisation si disponible.
Testez votre agent après l'import : Après avoir connecté du contenu web à un agent, testez-le en posant des questions qui devraient faire référence au contenu importé. Vérifiez que l'agent cite des informations précises provenant de vos sources web.
Dépannage
"Échec de la validation de l'URL"
Cause : L'URL est invalide, inaccessible ou bloquée par le site web.
Solution : Vérifiez que l'URL est correcte et accessible publiquement. Certains sites web bloquent le scraping automatisé. Essayez une autre URL ou contactez le propriétaire du site.
"Aucun contenu trouvé"
Cause : La page web ne contient pas de texte extractible (ex. : pages uniquement images, sites lourds en JavaScript).
Solution : Vérifiez que la page contient du texte lisible. Certains sites dynamiques peuvent ne pas être entièrement compatibles avec le scraping.
"Coût d'import trop élevé"
Cause : Le site web a des milliers de pages, entraînant une consommation élevée de crédits.
Solution : Utilisez le champ "URL à exclure" pour ignorer les pages inutiles, ou importez des pages spécifiques en utilisant l'import de page web à la place.
"L'agent ne trouve pas le contenu importé"
Cause : La source de données n'est pas connectée à l'agent, ou l'indexation n'est pas terminée.
Solution : Vérifiez que la source de données est connectée à votre agent dans les paramètres de la base de connaissances de l'agent. Vérifiez que le statut d'indexation affiche "À jour".
Étapes suivantes
Une fois que vous avez importé votre contenu web, vous êtes prêt à :
Créer un agent – Créez un agent IA personnalisé alimenté par votre contenu web.
Discuter avec vos données – Utilisez la fonction "Discuter avec cette source" pour interroger instantanément votre contenu importé.
Partager avec les coéquipiers – Donnez aux membres de l'équipe l'accès à votre base de connaissances.
Connecter à des agents – Liez votre source de données à des agents existants pour améliorer leurs capacités.
Votre contenu web est maintenant indexé, consultable et prêt à alimenter des flux de travail pilotés par l'IA dans votre espace de travail.
Ressources supplémentaires
Base de connaissances – Introduction – Apprenez ce qu'est une base de connaissances et pourquoi elle est importante.
Importer des documents / fichiers – Téléchargez des fichiers depuis votre ordinateur.
Importer depuis Google Drive – Synchronisez des fichiers depuis le stockage cloud.
Permissions et accès – Contrôlez qui peut voir et utiliser votre base de connaissances.
Créer un agent – Créez un agent et connectez-le à votre base de connaissances.
Prêt à importer votre premier site web ? Cliquez sur Connaissances dans la barre latérale, puis Importer → Importer un site web ou Importer une page web. Saisissez votre URL, configurez vos paramètres et laissez Swiftask s'occuper du reste.