15 juillet 2026
Bonjour,
Nous tenons à revenir vers vous suite aux incidents et ralentissements rencontrés récemment sur la plateforme Swiftask.
Ce qui s'est passé
Après investigation approfondie de nos équipes techniques, nous avons identifié que ces incidents étaient liés à des problèmes d'infrastructure survenus lors de pics de charge. Ces pics sont directement liés à la forte augmentation du volume d'adoption de la plateforme ces dernières semaines, ce qui a mis sous tension certains composants de notre architecture (services applicatifs, base de données, et ressources de calcul).
Ce que nous avons fait
Dès la détection de ces problèmes, nos équipes se sont mobilisée pour diagnostiquer précisément l'origine des ralentissements et déployer des correctifs, mis en production hier soir. Ces améliorations comprennent notamment :
L'optimisation du déploiement du moteur d'agents, afin d'éviter les interruptions en cours d'exécution ;
L'augmentation des ressources de la base de données, pour mieux absorber la charge de lecture/écriture ;
L'augmentation du nombre de serveurs de notre infrastructure, après avoir contacté Scaleway pour obtenir un relèvement de nos quotas.
Ce que nous continuons à faire
Nous poursuivons activement nos travaux d'optimisation, à la fois :
au niveau applicatif (gestion de la charge, optimisation des traitements, mise en place de mécanismes de résilience) ;
Optimization des support de LLM de type Scaleway ou autre (amelioration de la resiliance)
au niveau infrastructure (mise à l'échelle automatique, surveillance renforcée, gestion des ressources).
Par ailleurs, afin de garantir la fiabilité et la performance de la plateforme sur le long terme, nous avons mandaté un consultant externe spécialisé qui va réaliser un audit complet de notre infrastructure et nous accompagner dans la mise en œuvre d'améliorations supplémentaires à l'échelle globale de Swiftask.
Nous mettons tout en œuvre pour vous garantir un service stable et performant, et nous vous tiendrons informés de l'avancement de ces travaux.
Nous vous remercions pour votre confiance et votre patience.
Cordialement,
L'équipe Swiftask
7 juillet 2026

Anthropic vient de lancer deux nouveaux modèles Claude. Tous deux sont disponibles dès maintenant dans Swiftask, sur tous les plans, sans coût supplémentaire.
Lequel choisir ?
Les deux modèles partagent les mêmes spécifications :
Fenêtre de contexte de 992 000 jetons : analysez des bases de code entières ou des documents de 500 pages en une seule fois.
Limite de sortie de 120 000 jetons : des réponses détaillées sans coupure.
Disponibles sur les plans Pro, Team Starter, Team Growth et Custom.
Pourquoi passer de Sonnet 4.6 à Sonnet 5 ?
Sonnet 5 remplace Sonnet 4.6 comme recommandation par défaut pour la plupart des tâches. À niveau de prix équivalent, il offre un raisonnement plus précis et une fenêtre de contexte étendue. Si vous utilisez Sonnet 4.6 actuellement, vous pouvez librement passer à la version 5 si vous le voulez, c’est une amélioration immédiate en un clic.
Sonnet 4.6 reste disponible, aucun changement forcé, aucune interruption de vos flux de travail.
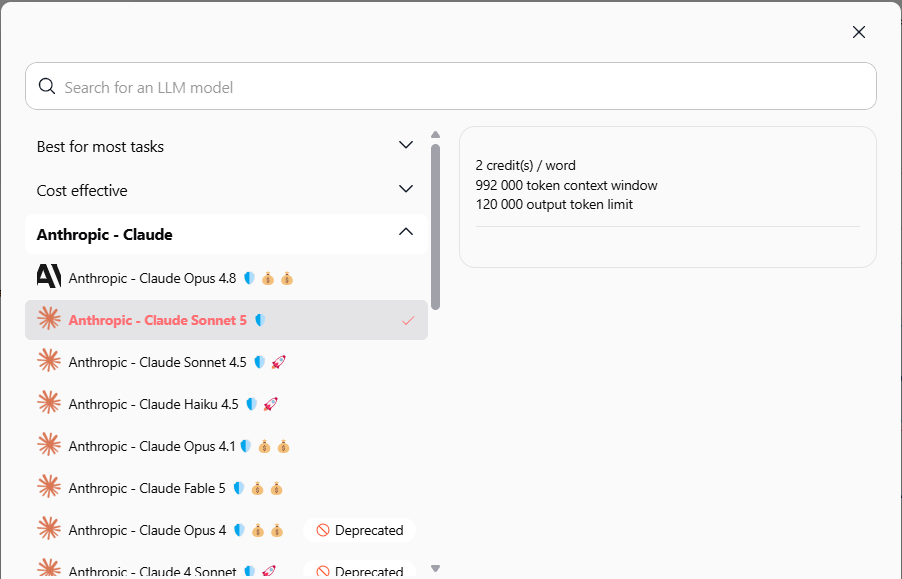
Comment basculer
Dans le Chat :
Ouvrez le Chat → cliquez sur le sélecteur de modèle en haut de la zone de saisie.
Sous "Anthropic - Claude", choisissez Sonnet 5 ou Fable 5.
Commencez à écrire.
Dans les Agents :
Ouvrez votre agent → Configuration de l'agent → Sélection du modèle.
Choisissez le nouveau modèle → Enregistrez.
Par défaut pour l'espace de travail : Administration de l'espace de travail → Paramètres → Avancé → IA de chat par défaut → sélectionnez le modèle → Mettez à jour.
Tester en 2 minutes
Sonnet 5 : Déposez un PDF de 50 pages et demandez : "Extrais les 10 insights les plus importants avec les références de pages." Comparez la vitesse et la précision avec votre modèle par défaut habituel.
Fable 5 : Donnez-lui une tâche de raisonnement complexe : "Analyse ces trois scénarios commerciaux et recommande le meilleur avec les compromis associés." Comparez la profondeur de la réponse avec celle de Sonnet 5.
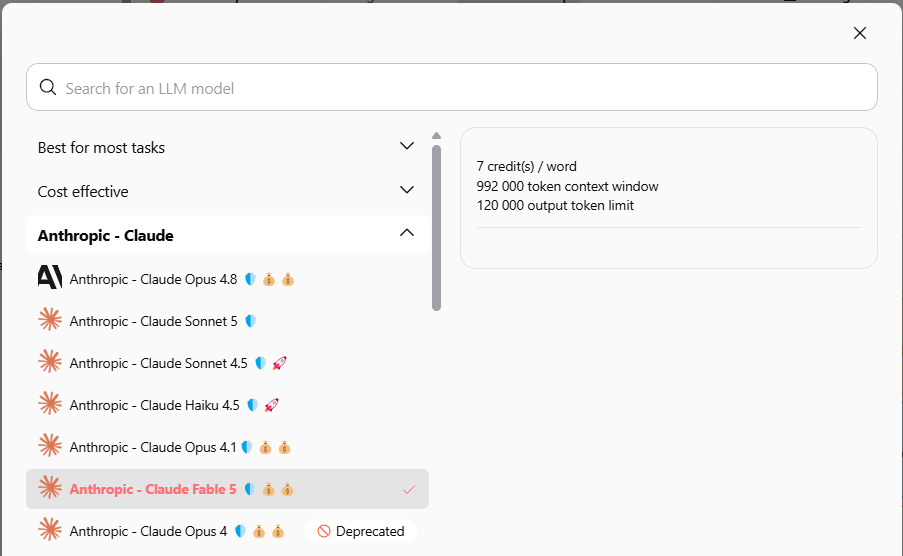
Notre recommandation
Utilisez Sonnet 5 pour 80 % de vos flux de travail : chat, agents, automatisations. Réservez Fable 5 pour les tâches où la qualité du résultat justifie le coût : analyse juridique, planification stratégique, audits techniques.
En savoir plus sur le choix du bon modèle et la consommation de crédits.
Ouvrez le Chat maintenant et essayez Sonnet 5 sur votre prochaine tâche.
Ce jeudi, rejoignez notre webinaire sur la création d’une flotte d’agents de cold-emailing pour gagner du temps dans votre prospection.
7 juillet 2026
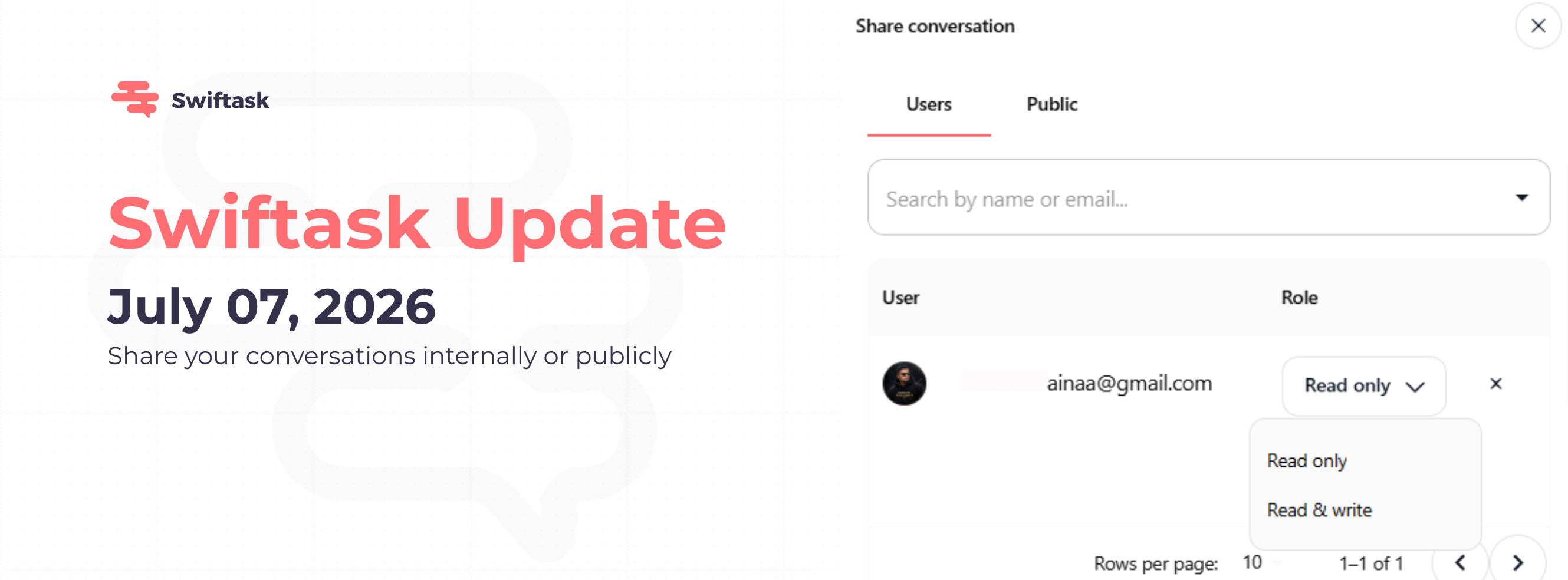
Nous avons simplifié la collaboration. Vous pouvez désormais partager n'importe quelle session de chat avec vos collaborateurs ou avec toute personne extérieure à votre espace de travail. Que vous ayez besoin de l'avis d'un collègue ou que vous souhaitiez présenter une analyse terminée à un client, le partage se fait en un seul clic.
Partagez vos conversations avec vos collaborateurs
Invitez vos collègues à consulter ou à modifier n'importe quelle session de chat. Chacun dispose du niveau d'accès nécessaire : « Lecture seule » pour examiner votre travail, ou « Lecture et écriture » pour participer et ajouter ses propres messages. Pour y accéder, cliquez sur le bouton Partager en haut de n'importe quelle conversation.
Deux niveaux d'autorisation : « Lecture seule » (consultation uniquement) ou « Lecture et écriture » (consulter, répondre et modifier ses propres messages).
Recherchez vos collaborateurs par nom ou par e-mail.
Gérez les accès à tout moment en rouvrant la boîte de dialogue de partage.

Partagez vos conversations publiquement via un lien
Besoin de partager un chat avec une personne extérieure à votre espace de travail ? Générez un lien public unique accessible sans connexion. C'est la solution idéale pour partager des résultats d'analyse avec des clients, obtenir des retours externes ou archiver des conversations pour référence.
Toute personne possédant le lien peut consulter la conversation en mode lecture seule.
Format du lien public :
https://www.app.swiftask.ai/public/chat/[slug]Révoquez l'accès à tout moment en désactivant le lien public.
Les destinataires ne voient que le fil de la conversation, pas de barre latérale, pas d'accès aux autres chats.

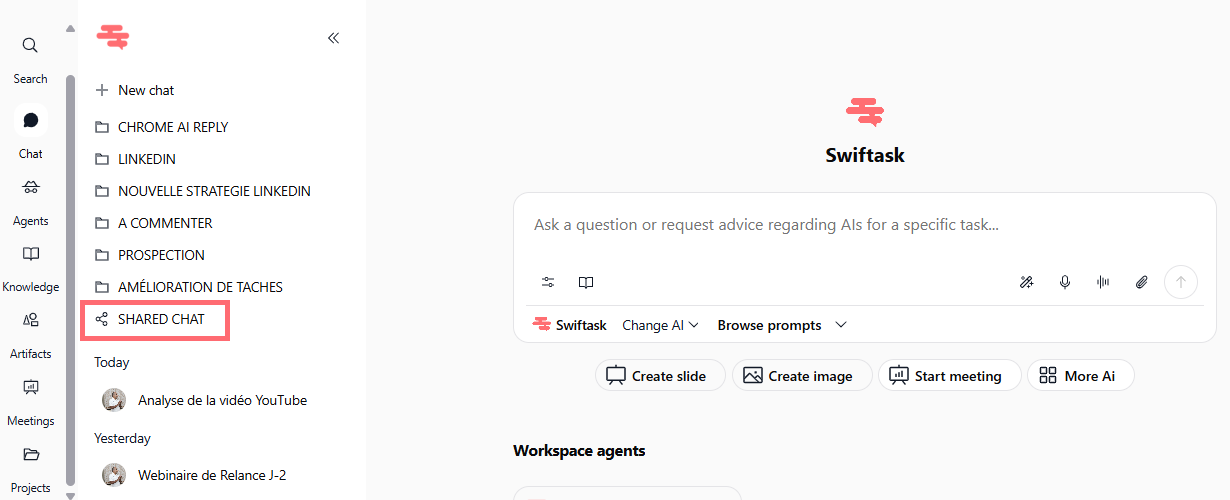
Retrouvez facilement les conversations partagées
Une nouvelle collection « Conversations partagées » est désormais disponible dans votre liste de sessions de chat, en bas des collections. Elle regroupe toutes les conversations qui ont été partagées avec vous ou auxquelles vous avez accès via des liens publics. Fini les recherches interminables dans votre historique de chat.
Comment tester cette fonctionnalité
Ouvrez n'importe quelle conversation et cliquez sur le bouton Partager (en haut à droite de l'en-tête du chat).
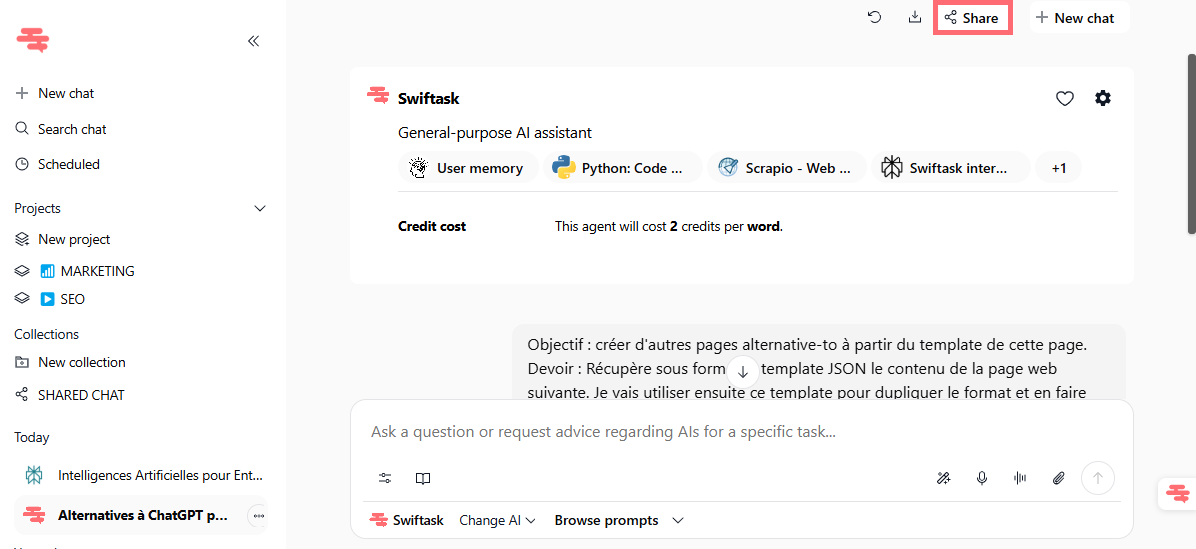
Dans l'onglet « Utilisateurs » : recherchez un collègue et attribuez-lui un accès « Lecture seule » ou « Lecture et écriture ».
Dans l'onglet « Public » : activez l'option « Toute personne disposant du lien » pour générer une URL partageable, puis copiez-la.
Envoyez le lien public à une personne extérieure à votre espace de travail, elle pourra l'ouvrir immédiatement sans avoir à s'inscrire.
Consultez votre liste de sessions de chat et accédez à la collection « Conversations partagées » en bas pour voir toutes vos conversations partagées.
Disponible sur tous les plans Swiftask. Ouvrez n'importe quelle conversation et cliquez sur Partager pour l'essayer.
Ce jeudi, rejoignez notre webinaire sur la création d’une flotte d’agents de cold-emailing pour gagner du temps dans votre prospection.
1 juillet 2026

Jusqu'à présent, pour suivre vos synchronisations automatiques de connaissances, vous deviez ouvrir chaque source l'une après l'autre. Aucune vue d'ensemble. Aucun contrôle centralisé. Aucune façon simple de savoir quand votre prochaine synchronisation aurait lieu.
Aujourd'hui, nous corrigeons cela.
✨ Nouveau : Menu de synchronisation automatique des connaissances
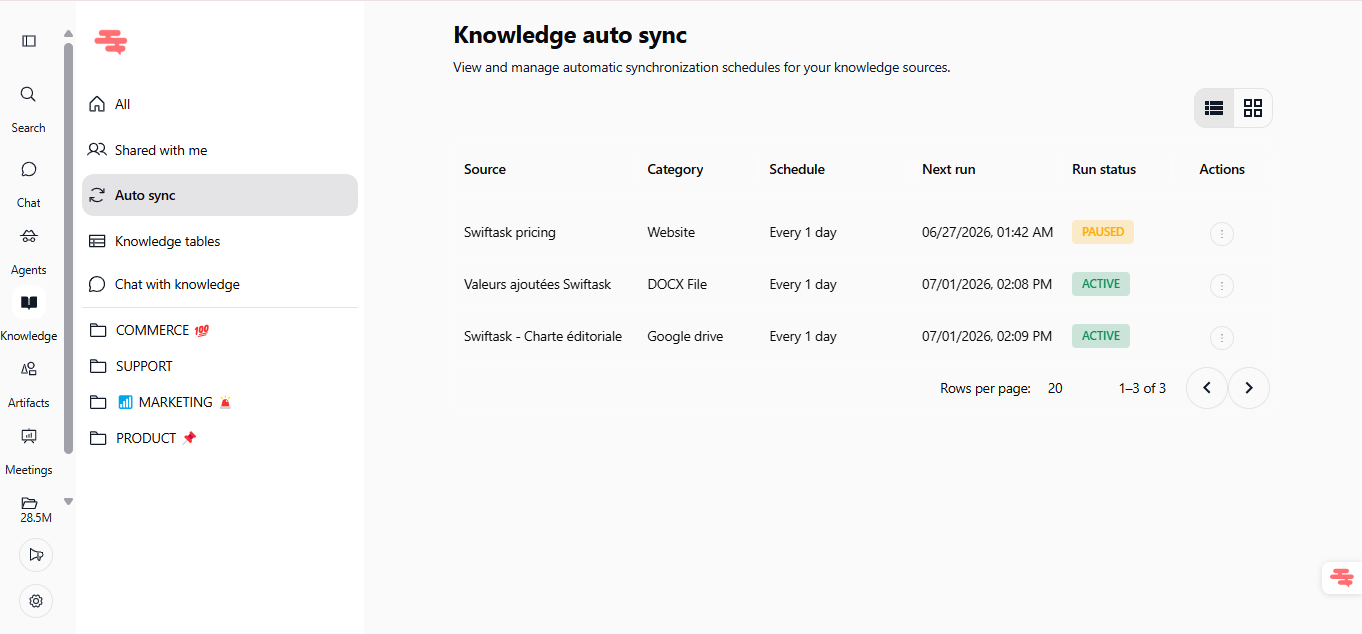
Un tableau de bord dédié pour visualiser, surveiller et contrôler chaque synchronisation automatique de vos sources de connaissances — en un seul clic.
Rendez-vous dans Connaissances → Synchronisation auto (barre latérale gauche).
Ce que vous obtenez :
Vue d'ensemble complète : source, catégorie, horaire, prochaine exécution et statut de chaque synchronisation active
Indicateurs de statut en temps réel : voyez instantanément ce qui est ACTIF ou EN PAUSE
Actions en un clic : mettez en pause, relancez ou supprimez n'importe quelle synchronisation sans quitter le tableau de bord
Propagation immédiate : les modifications sur vos sources synchronisées sont reflétées dans vos agents instantanément
Horaires flexibles : horaire, quotidien, hebdomadaire, mensuel — avec des intervalles personnalisés
Sources supportées : Google Drive, SharePoint, Dropbox, sites web et fichiers de documents
Disponible sur tous les plans : Pro, Team Starter, Team Growth et Custom
💡 Pourquoi c'est important
Vos agents ne sont performants que s'ils disposent de données à jour. Lorsque vos documents, drives et pages tarifaires sont mis à jour, vos agents doivent le savoir instantanément.
Le menu de synchronisation automatique vous donne la couche de contrôle qui manquait : moins de temps à surveiller vos synchronisations, plus de temps pour laisser votre IA travailler avec des données fraîches.
🧪 Essayez-le maintenant
Ouvrez Connaissances dans la barre latérale gauche
Cliquez sur Synchronisation auto
Consultez vos synchronisations actives et leurs prochaines exécutions prévues
Mettez en pause, relancez ou supprimez n'importe quelle synchronisation en un clic
Un tableau de bord. Chaque synchronisation. Contrôle total.
Rejoignez notre webinaire sur la création d’une flotte d’agents de cold-emailing pour gagner du temps dans votre prospection.
1 juillet 2026

Votre parc d'agents s'agrandit. Certains s'exécutent tous les jours, d'autres une fois par trimestre, et d'autres ne sont plus du tout utilisés. Vous pouvez désormais archiver les agents inactifs pour alléger votre espace de travail, et les restaurer en un clic dès que vous en avez besoin.
Archivez et restaurez en quelques secondes
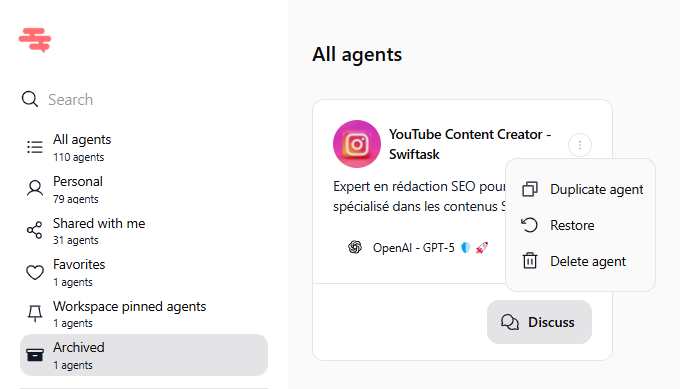
Archivez n'importe quel agent depuis le menu à trois points (⋮) sur la carte de l'agent.

Accédez à tous les agents archivés dans l'onglet « Archivés » de la barre latérale Agents.
Restaurez un agent archivé en un clic : toutes ses compétences, sources de connaissances et paramètres sont récupérés intacts.
Supprimez-le définitivement depuis la vue Archivés lorsque vous êtes sûr de ne plus en avoir besoin.
Le trouver : Agents → [Carte agent] → ⋮ → Archiver Le restaurer : Agents → Onglet Archivés → ⋮ → Restaurer
Que se passe-t-il lors de l'archivage d'un agent ?
L'agent disparaît de toutes les listes d'agents et des résultats de recherche, et passe dans l'onglet Archivés.
Les conversations existantes restent entièrement accessibles dans votre historique de chat, rien n'est perdu.
Les déclencheurs d'automatisation cessent de s'exécuter (tâches planifiées, déclencheurs par e-mail, etc.) jusqu'à ce que l'agent soit restauré.
L'accès partagé est suspendu : les utilisateurs avec qui vous avez partagé l'agent ne peuvent plus y accéder.
Lorsque vous restaurez l'agent, le partage est automatiquement réactivé pour tous les utilisateurs précédents, sans avoir besoin de le partager à nouveau manuellement.
Comment tester la fonctionnalité
Ouvrez la section Agents dans la barre latérale.
Choisissez un agent dont vous êtes propriétaire.
Cliquez sur le menu à trois points (⋮) → Archiver.
Vérifiez que l'agent a bien disparu de votre liste principale.
Accédez au nouvel onglet Archivés en bas de la barre latérale.
Cliquez sur ⋮ à côté de l'agent archivé → Restaurer.
L'agent est de retour dans votre liste principale, entièrement utilisable, avec tous les partages réactivés.
Disponible sur : Tous les plans (Pro, Team Starter, Team Growth, Custom)
📖 En savoir plus sur la gestion des agents →
Rejoignez notre webinaire sur la création d’une flotte d’agents de cold-emailing pour gagner du temps dans votre prospection.
1 juillet 2026

GLM-5.2 était déjà disponible sur Swiftask. Nous ajoutons maintenant une seconde version hébergée sur Scaleway, pour que vous puissiez utiliser la même puissance de raisonnement tout en gardant vos données en Europe.
Même modèle, hébergement souverain
Vous avez désormais deux façons d'utiliser GLM-5.2 dans Swiftask :
GLM-5.2 (version d'origine)
Scaleway - GLM-5.2 (nouveau, hébergé en Europe avec la protection Shield 3)
Mêmes capacités, même qualité de raisonnement. La différence, c'est l'endroit où vos données sont traitées.
Coût : 1.2 par mot
Hébergement : Scaleway, en Europe
Protection des données : Shield 3, vos données restent en Europe et ne sont jamais utilisées pour entraîner le modèle
Disponibilité : Tous les plans, sans coût supplémentaire
Accès : Déjà visible dans le sélecteur de modèles, aucune configuration nécessaire
Quand utiliser la version Scaleway
Choisissez Scaleway - GLM-5.2 quand :
Vous manipulez des données sensibles ou réglementées (finance, santé, secteur public)
Vous avez besoin de résidence européenne des données pour la conformité (RGPD, SecNumCloud)
Vous voulez garder votre flux de données dans une infrastructure européenne
Pour le reste, la version originale GLM-5.2 fait aussi bien le travail.
Comment l'utiliser
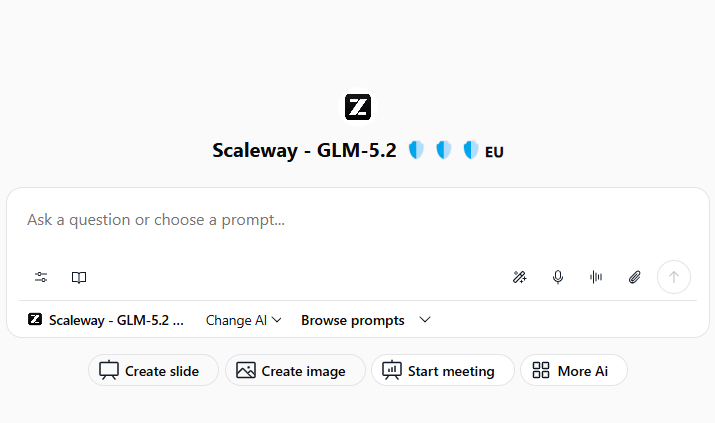
Dans Chat :
Ouvrez Chat
Cliquez sur le sélecteur de modèles en haut à gauche
Choisissez Scaleway - GLM-5.2
Dans les agents : Allez dans Agents → Configuration → Sélection du modèle et assignez Scaleway - GLM-5.2 à votre agent.
Ouvrez Chat, choisissez Scaleway - GLM-5.2 et laissez-le traiter vos tâches les plus complexes et les plus longues, tout en gardant vos données en Europe.
Rejoignez notre webinaire sur la création d’une flotte d’agents de cold-emailing pour gagner du temps dans votre prospection.
1 juillet 2026
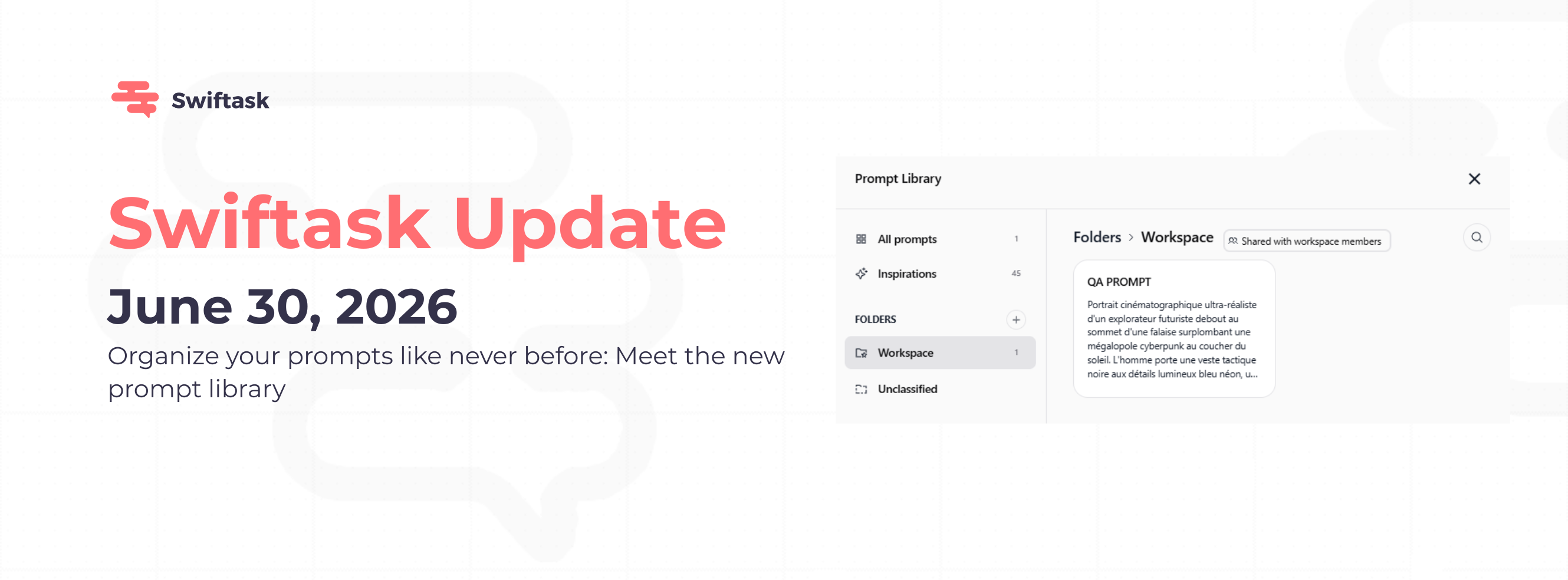
Vous vouliez une meilleure façon de gérer vos prompts. La voici. Organisez vos prompts par dossiers, partagez-les avec votre équipe et insérez-les dans le Chat en un clic, fini le défilement interminable d'une liste interminable.
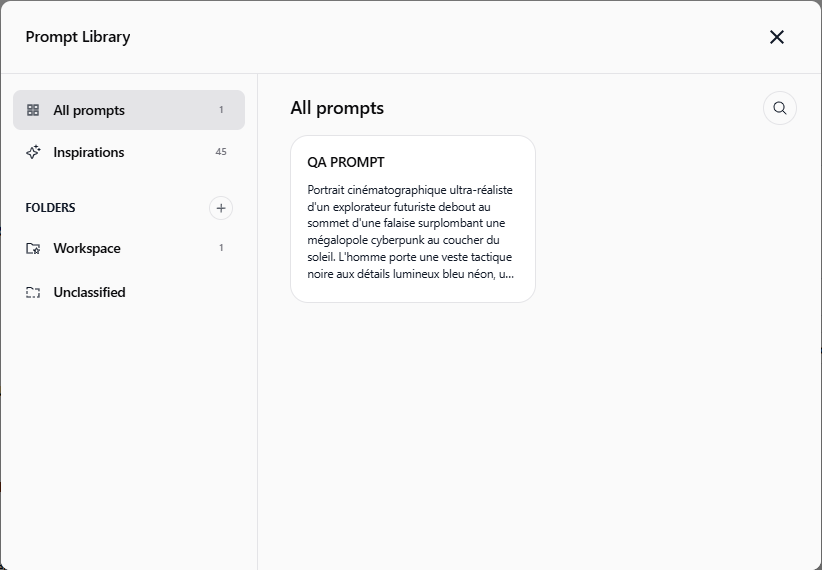
Pourquoi c'est important
Moins de temps à chercher. Moins de temps à copier. Moins de frictions pour les équipes qui utilisent les prompts quotidiennement.
Des prompts éparpillés dans une longue liste vous ralentissent. Les partager un par un est fastidieux. Et le copier-coller dans le Chat est une perte de temps. La nouvelle Bibliothèque de Prompts règle ces trois problèmes.
Des dossiers qui fonctionnent comme Notion ou Google Drive
Regroupez vos prompts par équipe, projet ou cas d'usage. Les dossiers gardent votre bibliothèque propre et facilitent la recherche.
Créez, renommez et supprimez des dossiers directement depuis la bibliothèque
Déplacez des prompts entre les dossiers en une seule action
Dossier Espace de travail, partagé avec votre équipe par défaut
Dossier Inspirations, prompts en lecture seule sélectionnés par Swiftask
Section Non classés pour les prompts qui ne sont pas encore triés
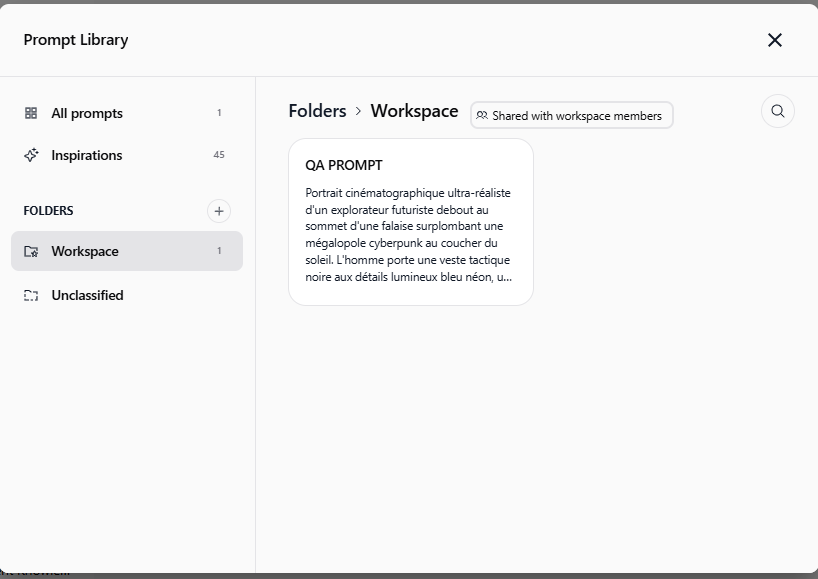
Partage par dossier avec accès basé sur les rôles
Partagez un dossier entier en une seule action au lieu de gérer chaque prompt individuellement. Ajoutez des utilisateurs ou des groupes, attribuez un rôle, et c'est prêt.
Utilisateur peut utiliser les prompts du dossier
Admin peut gérer les prompts et les membres
Propriétaire : contrôle total, incluant la suppression
Partagez avec des individus ou des groupes; une flexibilité totale pour chaque structure d'équipe
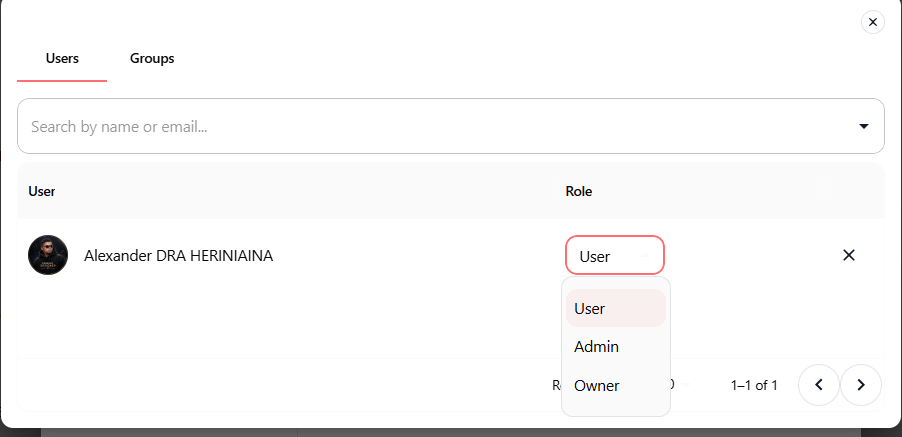
Un clic pour utiliser un prompt dans le Chat
Cliquez sur un prompt, appuyez sur Utiliser le prompt, et il s'insère dans votre champ de saisie Chat, prêt à être envoyé. Pour les prompts avec des valeurs dynamiques (#placeholders), remplissez les champs avant l'insertion.
Plus de copier-coller. Plus de changement de contexte.
Améliorations de l'interface et des performances
Barre latérale épurée avec des badges indiquant le nombre de prompts par dossier
Fil d'Ariane pour toujours savoir où vous vous trouvez
Recherche plus rapide sur l'ensemble de vos prompts
Navigation plus fluide dans les dossiers, même avec de grandes bibliothèques
Disponibilité
Disponible dès maintenant sur tous les plans Swiftask : Pro, Team Starter, Team Growth et Custom.
Essayez-le dès maintenant : ouvrez le Chat, cliquez sur Parcourir les prompts et commencez à organiser.
Rejoignez notre webinaire sur la création d’une flotte d’agents de cold-emailing pour gagner du temps dans votre prospection.
30 juin 2026

On a ajouté un nouvel assistant de recherche qui trouve les infos sur le web et vous rapporte des images, des liens et des réponses claires. Plus besoin de jongler entre Swiftask et Google.
Votre nouveau compagnon de recherche
Découvrez votre nouvel assistant de recherche web. Posez-lui n'importe quelle question que vous taperiez sur Google : "Quelles sont les dernières news sur [sujet] ?" ou "Montre-moi les prix de la concurrence" , et il vous répond avec des images, des sources cliquables et des résumés faciles à comprendre.
- Cherche sur le web et affiche des images
- Vous donne des liens cliquables vers les sources

- Affiche des extraits pour comprendre le contexte
- S'utilise directement dans le Chat avec vos autres agents
- Disponible pour tout le monde, sans configuration
Comment l'utiliser :
1. Ouvrez le Chat
2. Cliquez sur le sélecteur d'agents en bas à gauche
3. Choisissez "Web Search Assistant"
4. Posez votre question
5. Recevez vos résultats avec images et sources
Essayez-le :
Posez une question comme : "Que disent les gens sur [sujet] ?" ou "Trouve-moi des infos sur [entreprise]" et vous verrez les résultats s'afficher avec des images et des sources cliquables.

C'est aussi simple que ça. Des recherches plus efficaces, sans changer d'onglet. 🔍
Rejoignez notre webinaire sur la création d’une flotte d’agents de cold-emailing pour gagner du temps dans votre prospection.
25 juin 2026
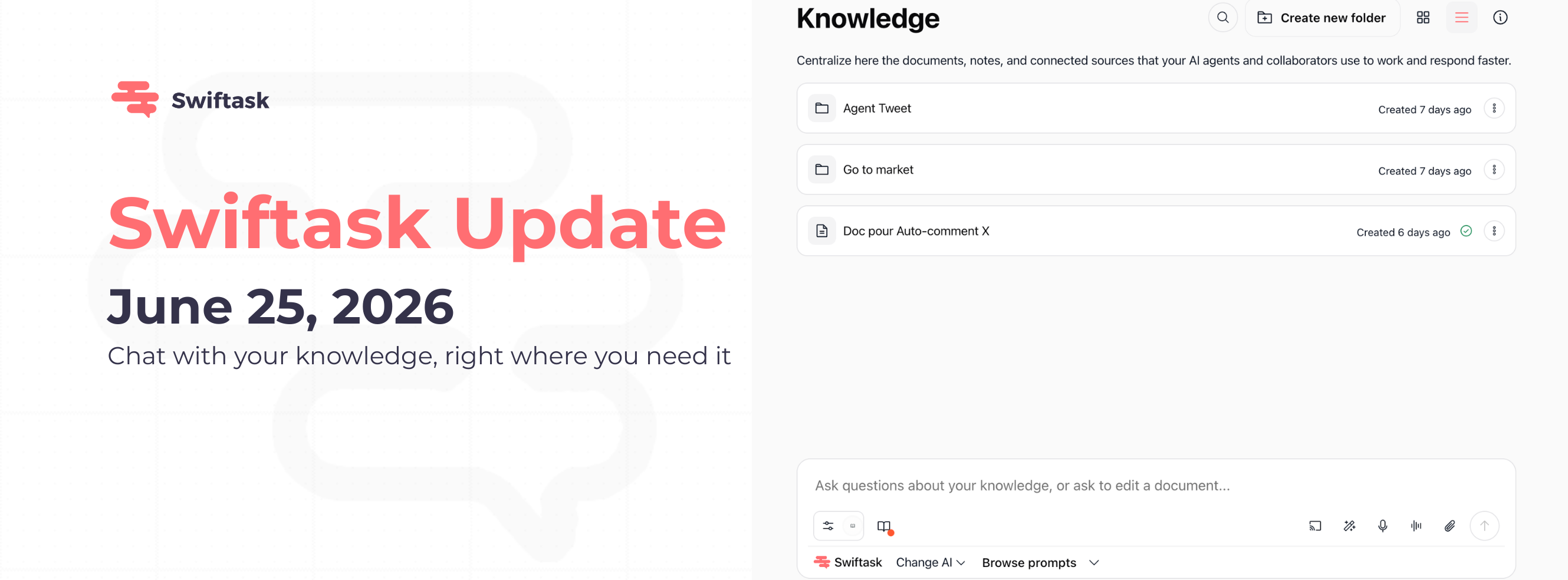
Nous sommes ravis d'introduire le Chat directement dans votre base de connaissances (Knowledge). Plus besoin de passer d'un écran à l'autre, plus de perte de contexte. Posez des questions sur vos documents, demandez des modifications et travaillez avec l'IA, le tout au même endroit.
Chat dans Knowledge : Posez des questions et modifiez vos documents instantanément
Vous pouvez désormais chatter avec l'IA directement depuis l'interface Knowledge. Que vous exploriez des documents ou que vous construisiez votre base de connaissances, le champ de saisie du chat est toujours visible en bas de l'écran, prêt à recevoir vos questions et vos demandes.
Posez des questions sur n'importe quel document de votre base de connaissances
Demandez des modifications ou des éditions de vos documents
Sélectionnez des documents spécifiques pour cibler vos questions
Basculez entre les différents modèles d'IA grâce au menu déroulant « Change AI »
Fonctionne de manière fluide sur tous vos documents, sans aucune limite
Disponible sur tous les plans : Pro, Team Starter, Team Growth et Custom
Comment le tester : Ouvrez Knowledge → Sélectionnez ou parcourez vos documents → Utilisez le champ de saisie du chat en bas de l'écran (« Ask questions about your knowledge, or ask to edit a document... ») → Tapez votre question ou votre demande de modification → Choisissez votre Agent IA préféré dans le menu déroulant « Change AI » → Appuyez sur Entrée pour obtenir une réponse instantanée concernant vos documents.
Où le trouver : Knowledge → En bas de l'interface (toujours visible lors de la consultation de documents)
Et voilà ! Votre équipe peut désormais travailler avec les documents et l'IA dans un espace unifié, éliminant ainsi la friction liée au passage entre Knowledge et Chat.
24 juin 2026

Vous pouvez maintenant choisir entre trois modèles de pointe selon vos besoins et votre budget. Tous sont disponibles immédiatement dans votre Sélecteur de modèle de chat et votre Configuration de l'agent, sur tous les forfaits.
Kimi 2.7 Code (Moonshot AI)
Haute performance, budget maîtrisé.
Moonshot a conçu un modèle offrant des résultats exceptionnels tout en consommant 30 % de puissance de calcul en moins que son prédécesseur. Idéal pour les équipes déployant un volume important d'agents et de workflows.
0,6 crédit / mot : le choix le plus économique de cette sélection
Excellentes performances pour les tâches complexes et les workflows multi-étapes
Idéal pour les équipes souhaitant passer à l'échelle avec des agents IA tout en maîtrisant les coûts
GLM-5.2 (Z.ai)
Compréhension profonde, contexte illimité, prix équitable.
Z.ai a créé un modèle capable de lire des projets entiers d'une traite. Idéal si vous avez besoin d'analyser des documents longs, des bases de code massives ou de coordonner des workflows complexes.
0,9 crédit / mot : un bon compromis entre coût et capacité
Peut absorber l'équivalent d'une petite bibliothèque en une seule requête
Excellent pour les analyses multi-documents et les workflows autonomes de longue durée
Claude Opus 4.8 (Anthropic)
La fiabilité premium pour les tâches critiques.
Anthropic a créé le modèle le plus fiable du marché pour les décisions importantes. Il détecte ses propres erreurs 4 fois mieux que la génération précédente et pense avant d'agir pour les problèmes complexes.
3,48 crédits / mot : le modèle premium
Recommandé pour les workflows d'entreprise où la précision est non-négociable
Idéal pour les tâches qui demandent du jugement, de la rigueur et une haute fiabilité
Comment choisir ?
Des tâches volumineuses avec un budget limité ? Optez pour Kimi 2.7 Code pour optimiser vos coûts.
Projets complexes ou longs documents ? Préférez GLM-5.2 pour sa capacité de contexte.
Décisions critiques ou tâches d'entreprise ? Investissez dans Claude Opus 4.8 pour la fiabilité.
Vous pouvez utiliser les trois en même temps dans votre workspace, choisissez le meilleur modèle pour chaque agent.
Améliorations
Changement de modèle instantané : Passez d'un modèle à l'autre dans la Configuration de l'agent sans recharger la page.
Informations clés en un coup d'œil : Le Sélecteur de modèle de chat affiche le coût et les capacités principales pour chaque modèle, facilitant votre choix.
Accédez-y maintenant : Ouvrez votre Sélecteur de modèle de chat ou créez un nouvel agent pour tester votre premier modèle de pointe.